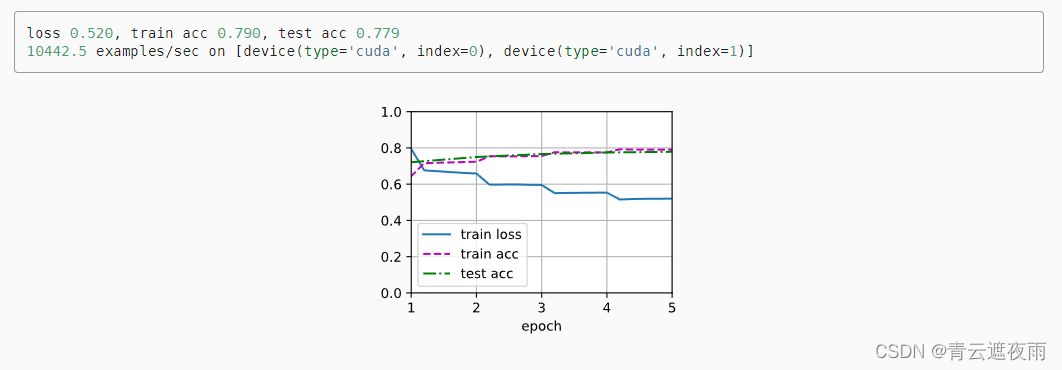
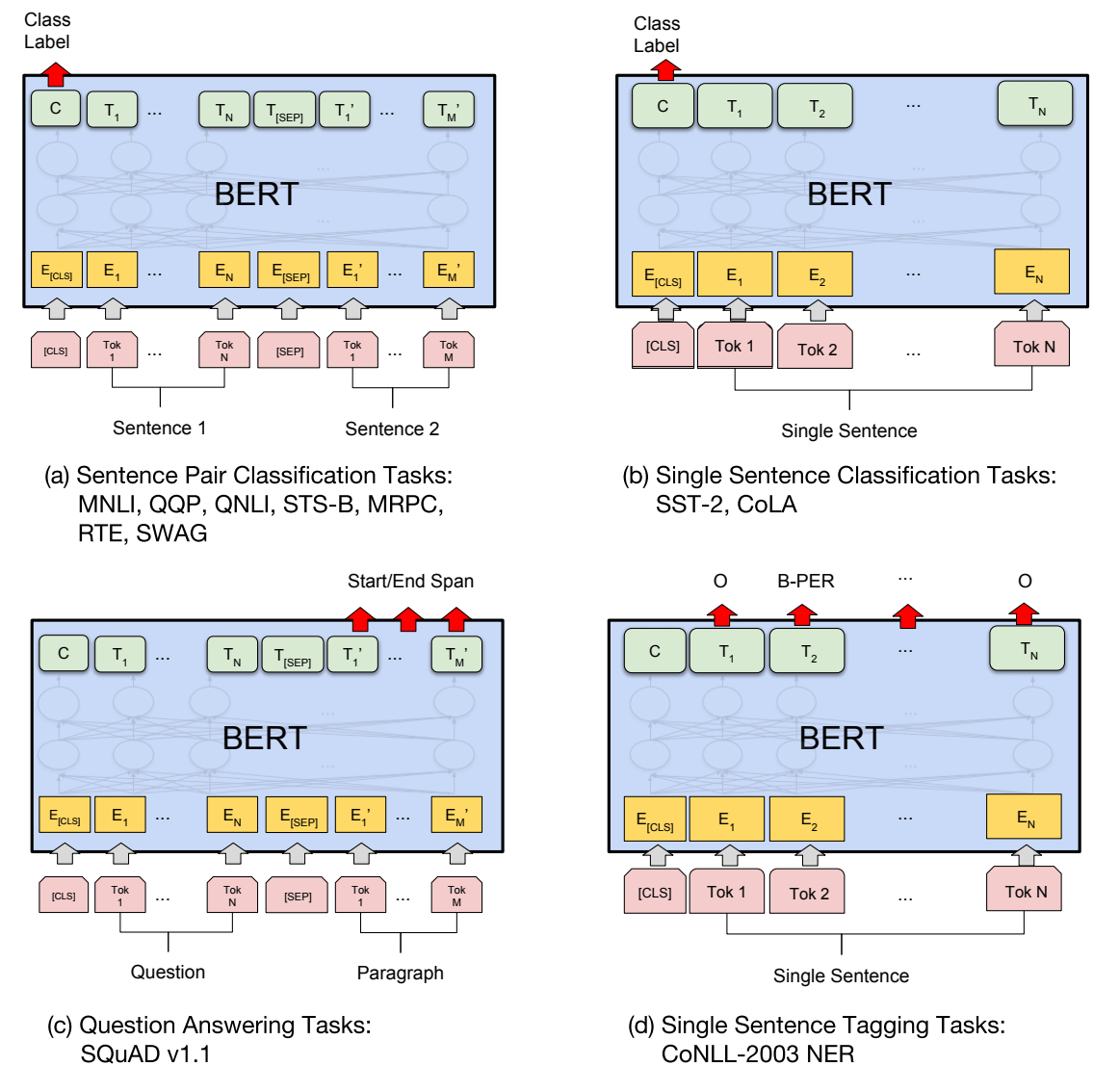
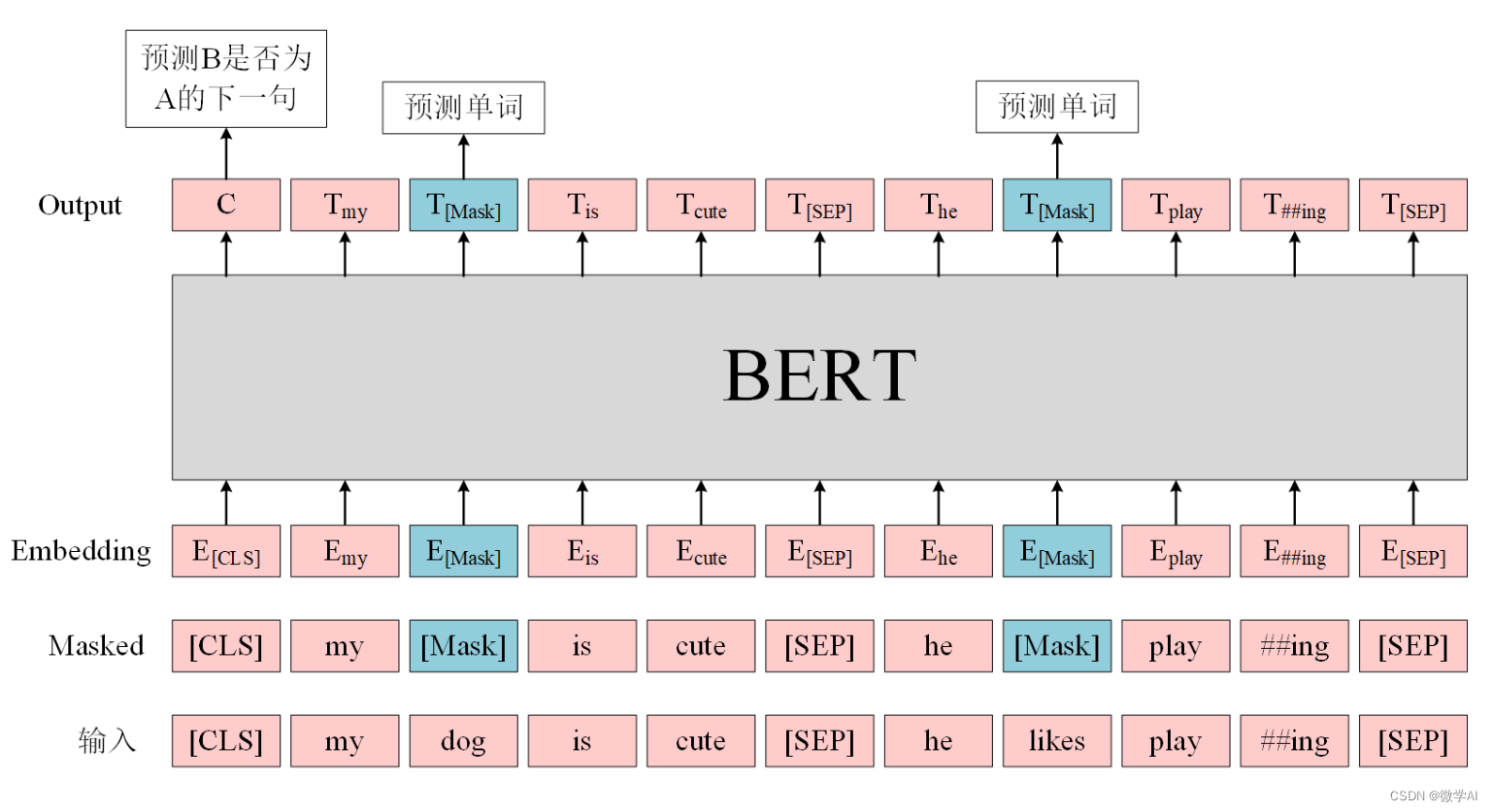
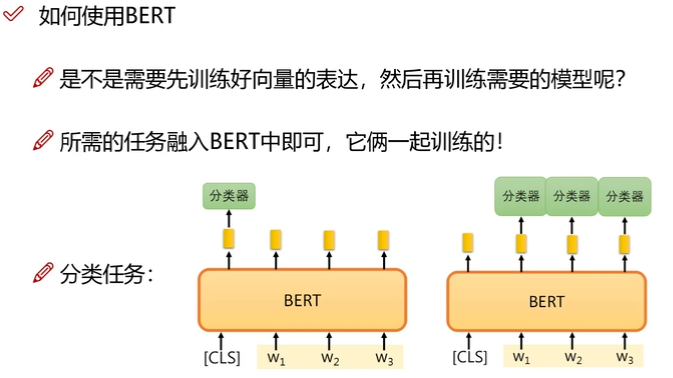
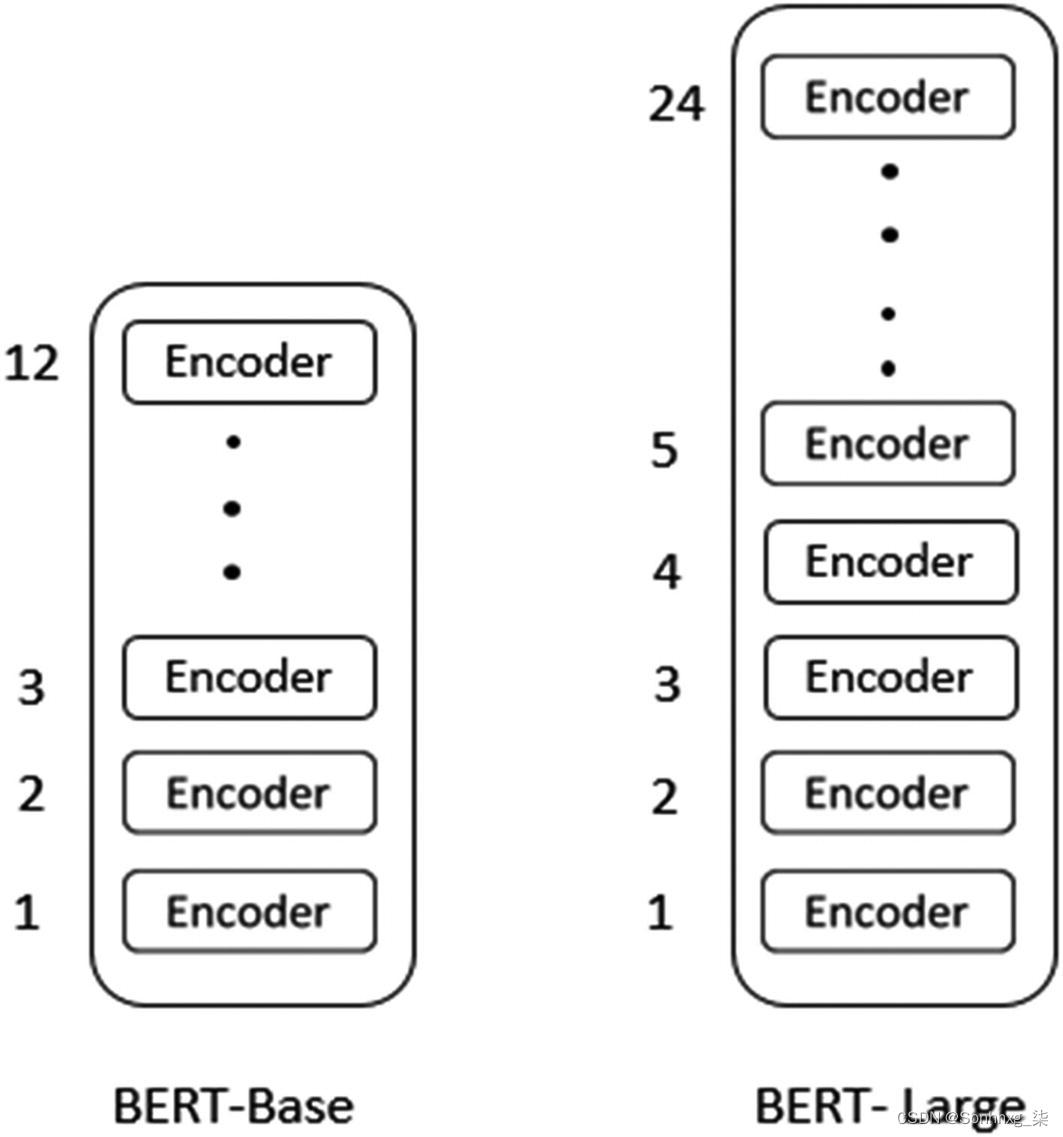
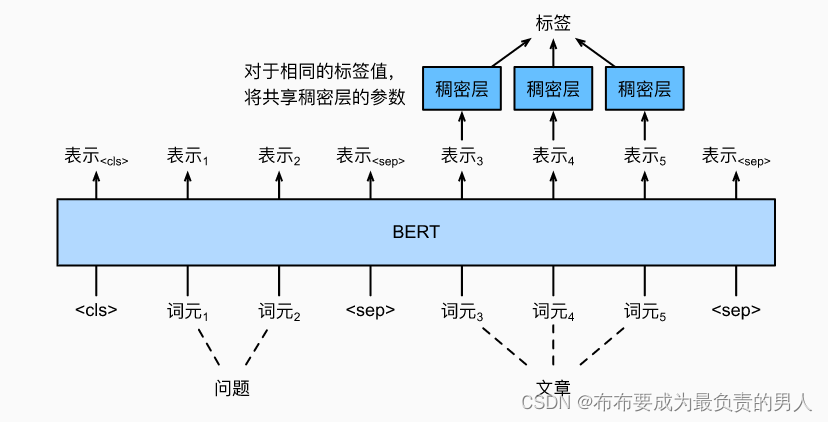
vue
笔试题
虚拟机
存储型XSS
MCAL
PSO粒子群优化
数据卷
easyui
iot
springmvc
算法的时间复杂度和空间复杂度
hevc
流媒体
热成像仪
魔百盒固件
startup packet
内网渗透
邮件营销
GO111MODULE=off
企业
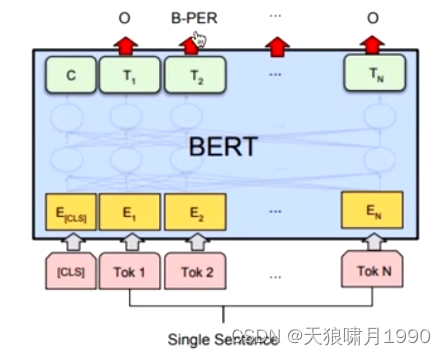
bert
2024/4/11 15:42:07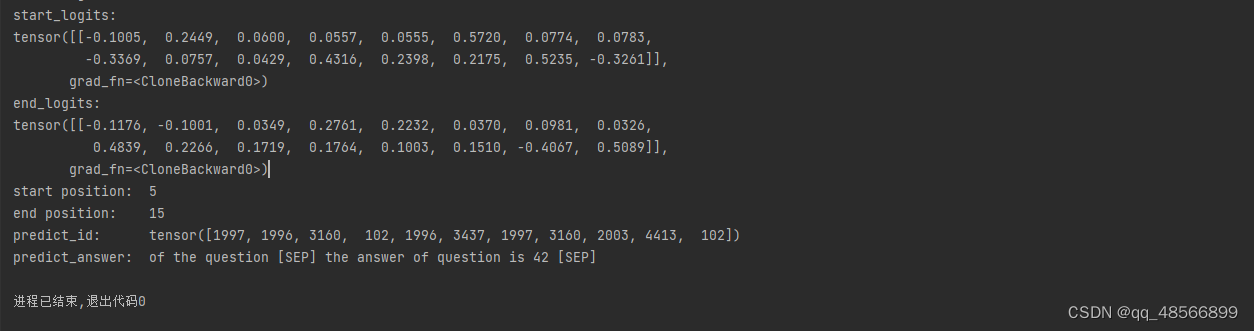
bert----学习笔记
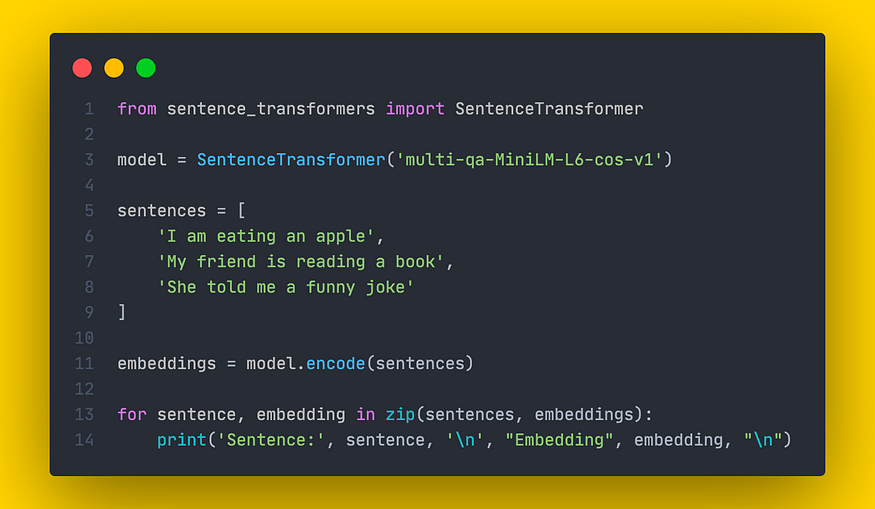
一个简单基础模板: bert导入,分词,编码
from transformers import BertConfig, BertTokenizer, BertModel
import torch
from transformers import BertModel, BertTokenizer
# 指定模型文件夹路径(包含 pytorch_model.bin&#…

预训练语言模型与其演进
目录 前言1 语言模型2 预训练语言模型3 预训练语言模型的演进3.1 word2vec:开创预训练时代3.2 Pre-trained RNN3.3 GPT:解决上下文依赖3.4 BERT:双向预训练的革新 4 GPT与BERT的对比5 其他模型:Robust BERT和ELECTRA5.1 Robust BE…

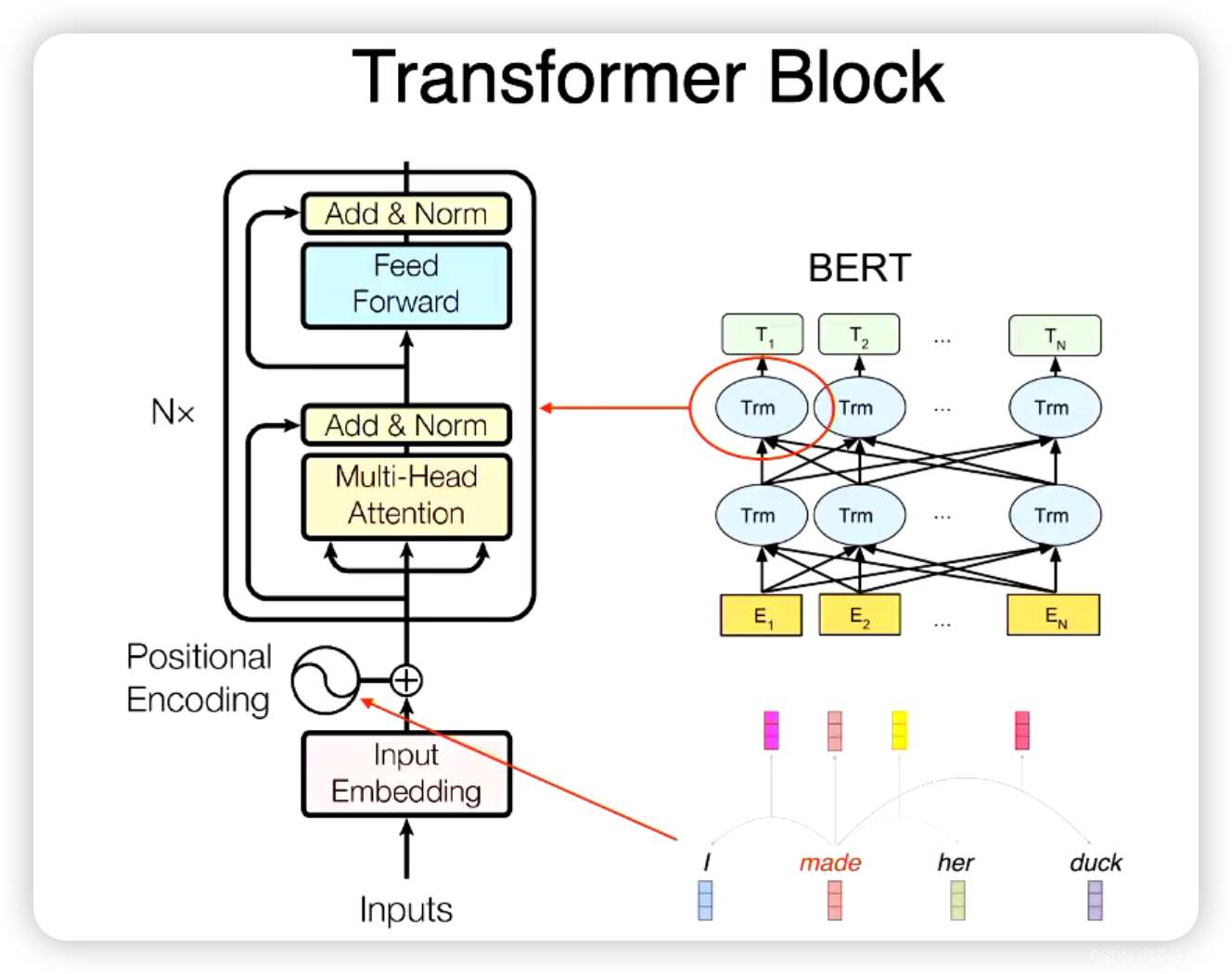
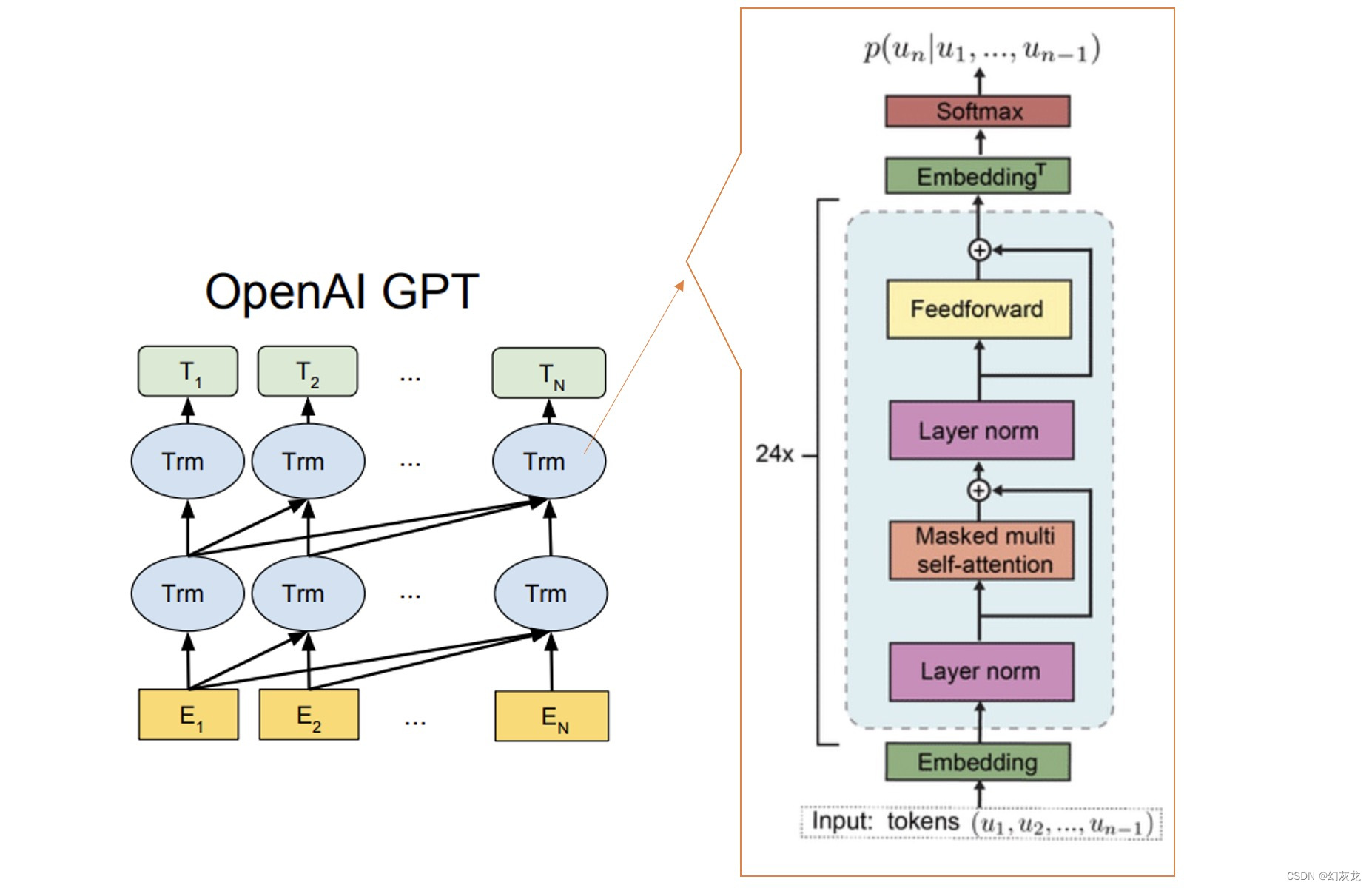
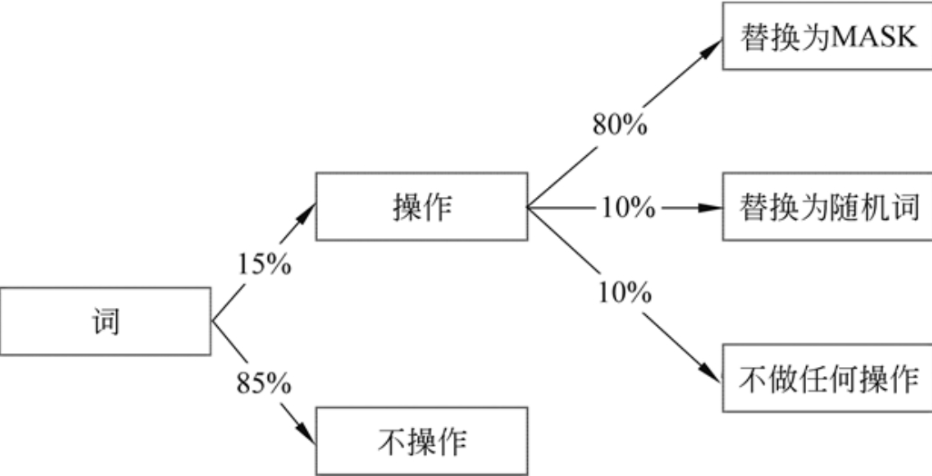
从Attention到Bert——3 BERT解读
上一篇 从Attention到Bert——2 transformer解读 文章目录Bert介绍Bert模型结构1 与GPT,ELMO结构对比2 Bert的输入3 Bert的输出Bert两大预训练任务MLM, NSP1 CV的预训练任务2 Masked language model, MLM 掩码语言模型3 Next sentence predict,NSP&#…

TinyBERT论文及代码详细解读
简介
TinyBERT是知识蒸馏的一种模型,于2020年由华为和华中科技大学来拟合提出。
常见的模型压缩技术主要分为:
量化权重减枝知识蒸馏
为了加快推理速度并减小模型大小,同时又保持精度,Tinybert首先提出了一种新颖的transforme…

Sentence-BERT 语义相似度双塔模型
论文介绍
发表:2019,EMNLP 论文题目:《Sentence-BERT:sentence embeddings using siaese BERT-networks》 论文地址:https://arxiv.org/abs/1908.10084 Github:https://github.com/UKPLab/sentence-transformers 适用领域&#x…

自定义 bert 在 onnxruntime 推理错误:TypeError: run(): incompatible function arguments
自定义 bert 在 onnxruntime 推理错误:TypeError: run(): incompatible function arguments 自定义 bert 在 onnxruntime 推理错误:TypeError: run(): incompatible function arguments推理代码错误提示核心错误 解决方法核对参数…
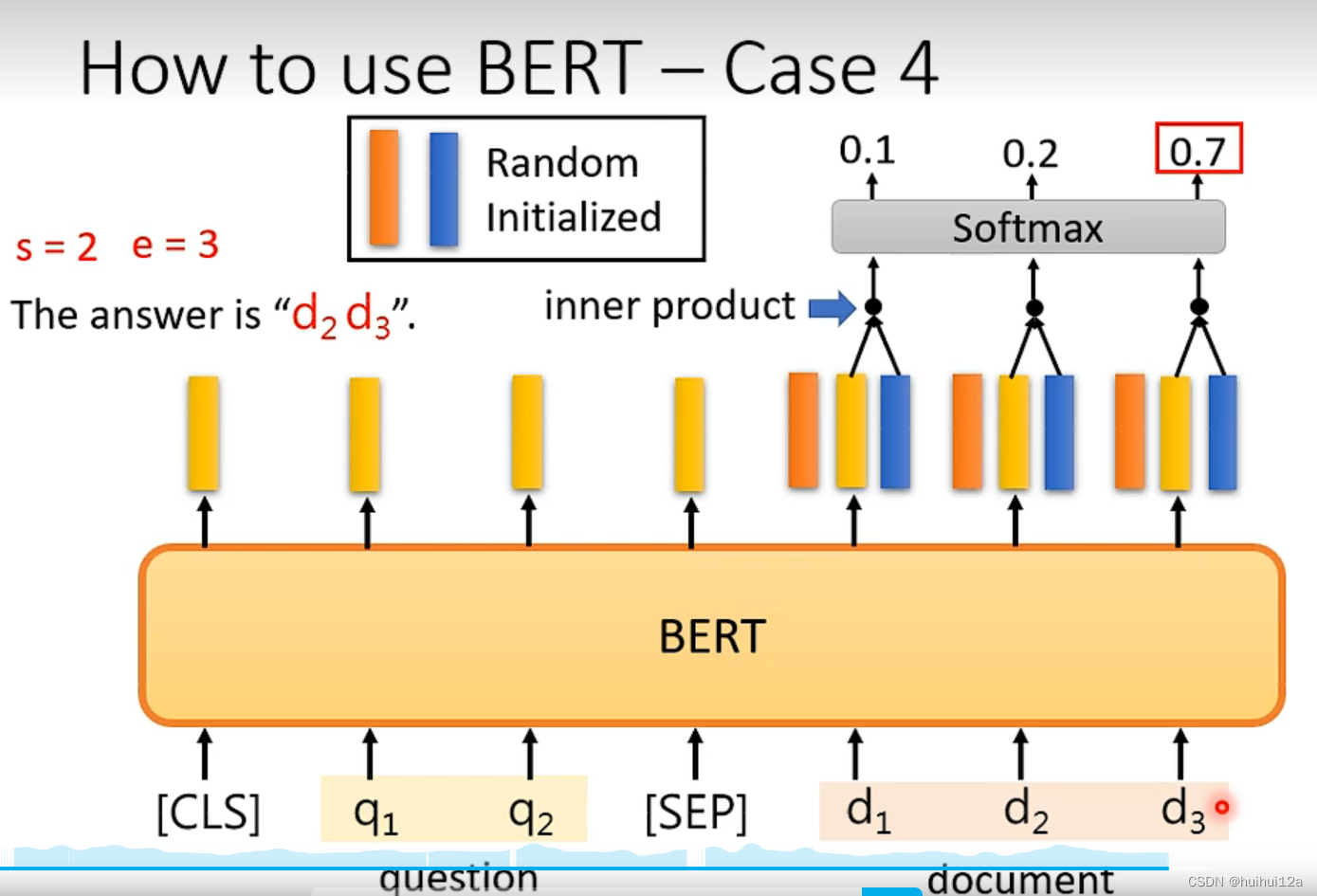
![[oneAPI] 基于BERT预训练模型的SQuAD问答任务](https://img-blog.csdnimg.cn/329e4dd5873f488ca6ee22c97fefe5b4.png)
[oneAPI] 基于BERT预训练模型的SQuAD问答任务
[oneAPI] 基于BERT预训练模型的SQuAD问答任务 Intel Optimization for PyTorch and Intel DevCloud for oneAPI基于BERT预训练模型的SQuAD问答任务语料介绍数据下载构建 模型 结果参考资料 比赛:https://marketing.csdn.net/p/f3e44fbfe46c465f4d9d6c23e38e0517 Int…

读书笔记:多Transformer的双向编码器表示法(Bert)-4
多Transformer的双向编码器表示法
Bidirectional Encoder Representations from Transformers,即Bert;
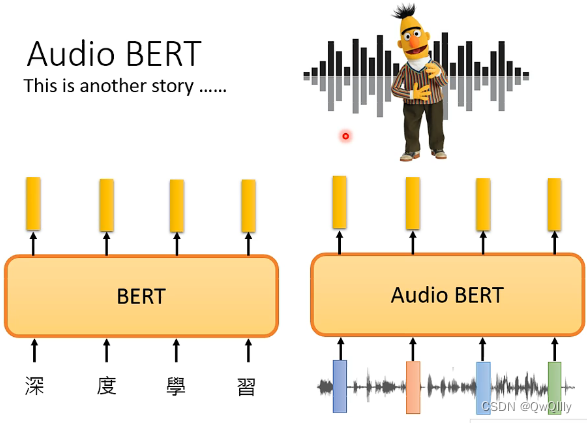
第二部分 探索BERT变体 从本章开始的诸多内容,以理解为目标,着重关注对音频相关的支持(如果有的话)…

BERT、ERNIE、Grover、XLNet、GPT、MASS、UniLM、ELECTRA、RoBERTa、T5、C4
BERT、ERNIE、Grover、XLNet、GPT、MASS、UniLM、ELECTRA、RoBERTa、T5、C4 ELMOBERTERNIEGroverXLNetGPTMASSUniLMELECTRARoBERTaT5C4ELMO BERT
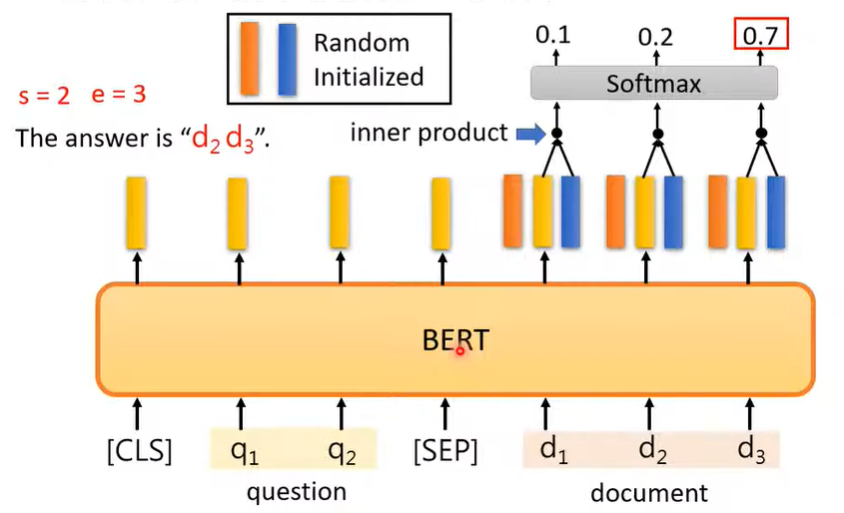
李宏毅-hw7-利用Bert完成QA
一、查漏补缺、熟能生巧: 只有熬过不熟练的时期,反复琢磨,才会有熟练之后,藐视众生的时刻
1.关于transformers中的tokenizer的用法的简单介绍:
from transformers import BertTokenizerFast# 加载预训练的BERT模型to…

3 文本分类入门finetune:bert-base-chinese
项目实战:
数据准备工作 bert-base-chinese 是一种预训练的语言模型,基于 BERT(Bidirectional Encoder Representations from Transformers)架构,专门用于中文自然语言处理任务。BERT 是由 Google 在 2018 年提出的一…
读书笔记:多Transformer的双向编码器表示法(Bert)-3
多Transformer的双向编码器表示法
Bidirectional Encoder Representations from Transformers,即Bert;
第3章 Bert实战
学习如何使用预训练的BERT模型:
如何使用预训练的BERT模型作为特征提取器;探究Hugging Face的Transforme…

2020深度文本匹配最新进展:精度、速度我都要!【阅读笔记】
一、总结
原文:https://mp.weixin.qq.com/s/UcNhNgiASKhxBbcXGEz0tw
二、其他资料
PolyEncoder-Facebook的全新信息匹配架构-提速3000倍(附复现结果与代码):https://zhuanlan.zhihu.com/p/119444637

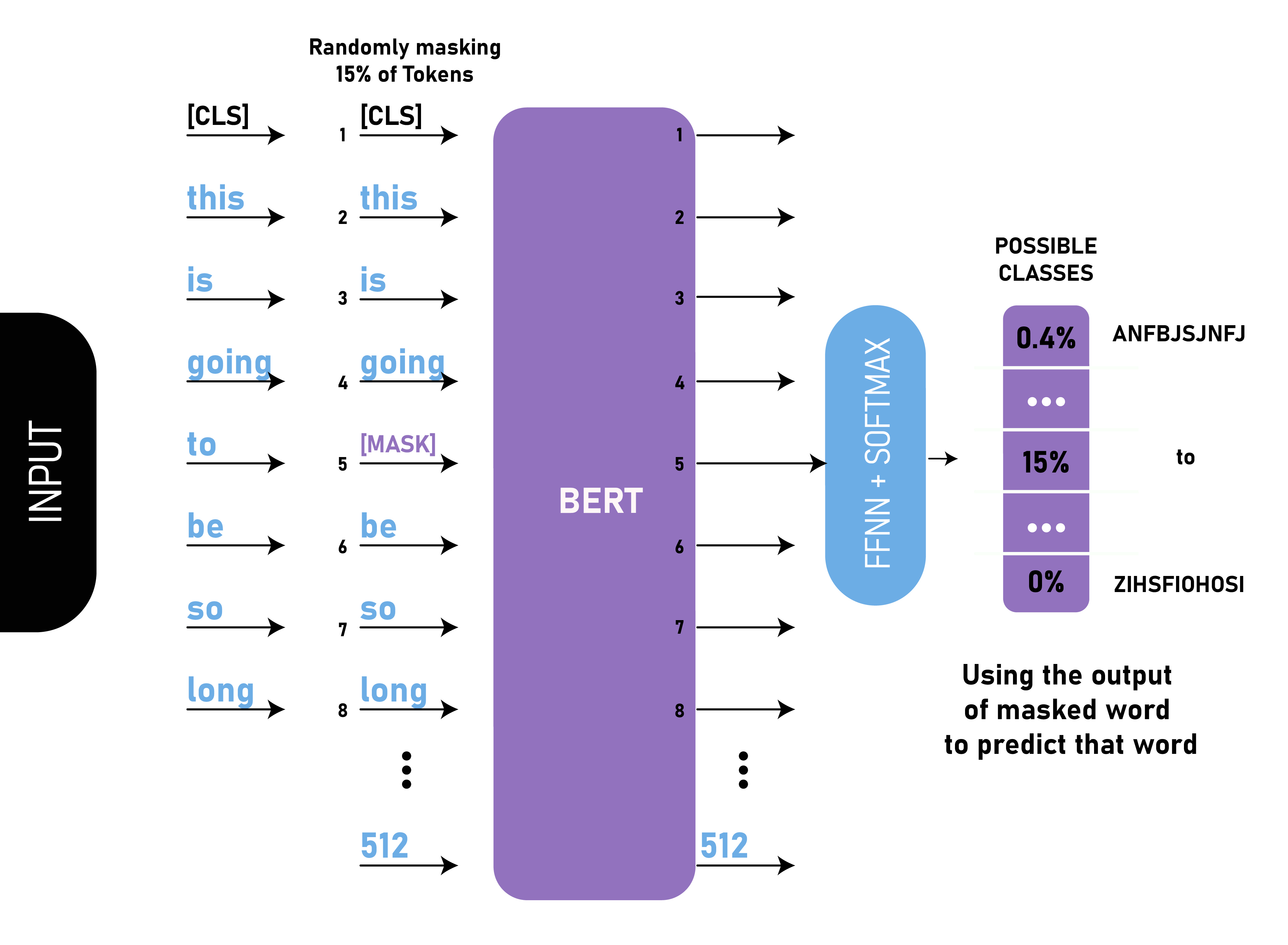
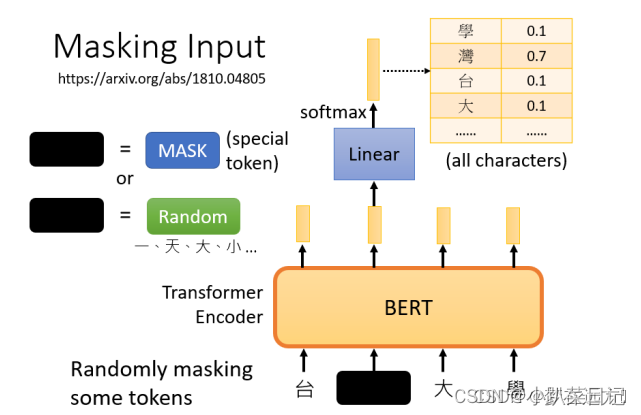
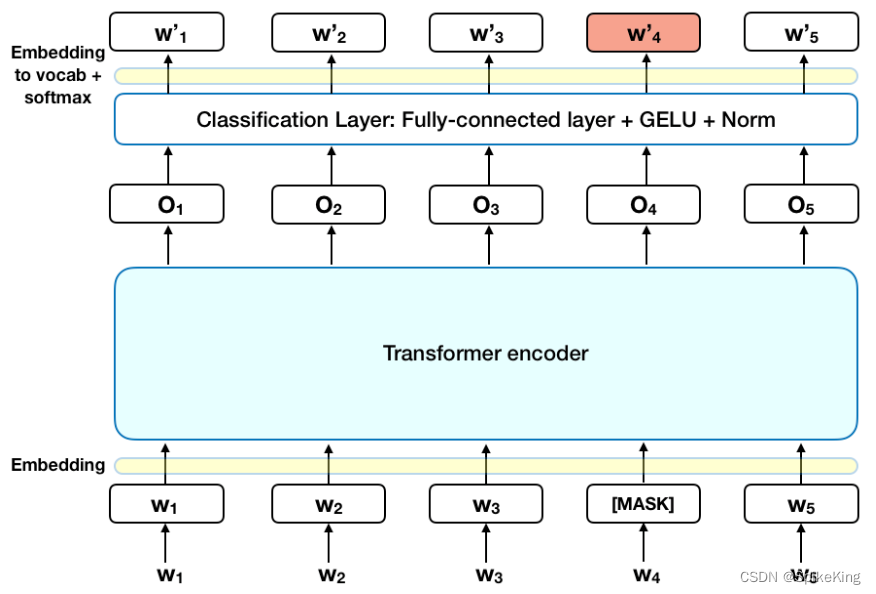
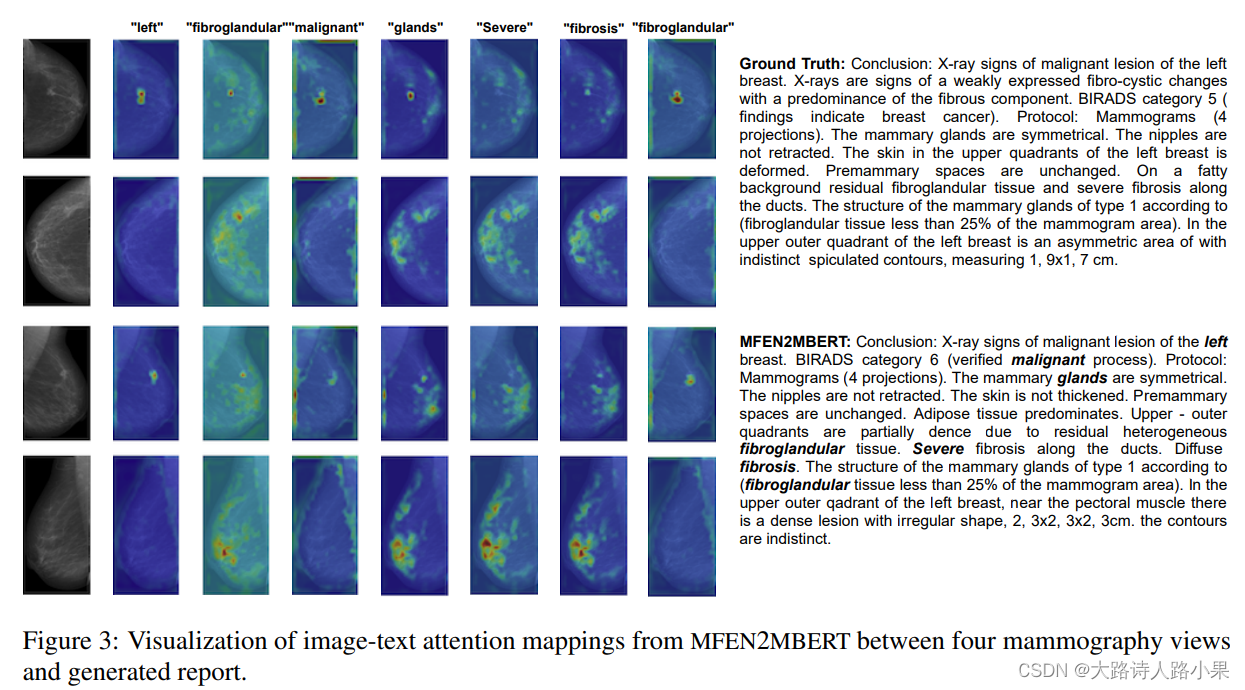
bert中为什么要这么msdk(80% mask, 10% 随机替换,10% 保持原词)
bert在训练阶段不是将15%的词汇MASK掉,从而采用自监督的方式训练模型,那我直接将这15%mask掉不就好了吗,为什么又要进行80% mask,10% 随机替换,10% 保持原词呢?起初我看到的时候也比较迷惑,下面…
基于transformer一步一步训练一个多标签文本分类的BERT模型
Bert(Bidirectional Encoder Representations from Transformers)是一种基于Transformer架构的预训练语言模型,由Google在2018年提出。Bert模型在自然语言处理领域取得了重大突破,被广泛应用于各种NLP任务,如文本分类、命名实体识别、问答系统等。
Bert模型的核心思想是通…


DEBERTA: DECODING-ENHANCED BERT WITH DIS- ENTANGLED ATTENTION glue榜首论文解读
一、概览 二、详细内容
abstract a. 两个机制来improve bert和 roberta ⅰ. disentangled attention mechanism ⅱ. enhanced mask decoder b. fine-tuning阶段 ⅰ. virtual adversarial training -> 提升泛化 c. 效果 ⅰ. 对nlu和nlg下游任务,提升都比较大 ⅱ.…
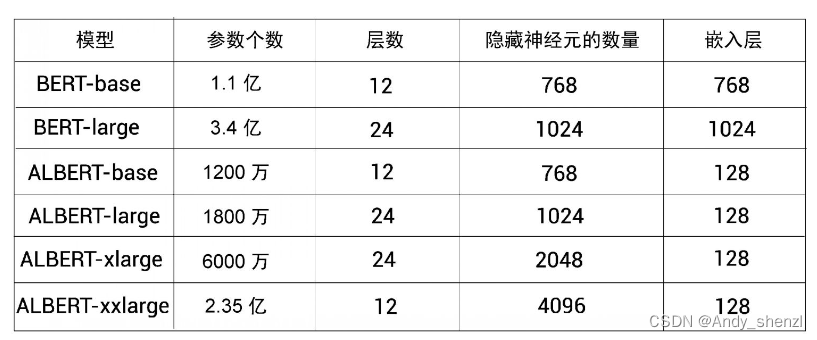
BERT和ALBERT的区别;BERT和RoBERTa的区别;与bert相关的模型总结
一.BERT和ALBERT的区别:
BERT和ALBERT都是基于Transformer的预训练模型,它们的几个主要区别如下: 模型大小:BERT模型比较大,参数多,计算资源消耗较大;而ALBERT通过技术改进,显著减少…

基于Bert的语义相关性建模
文章目录搜索相关性定义字面相关性语义相关性1 传统语义相关性模型2 深度语义相关性模型基于表示的匹配sentence representation基于交互的匹配sentence interaction两种方法的优缺点比较基于Bert的语义相关性建模1 基于表示的语义匹配——Feature-based思想缺点:2 …
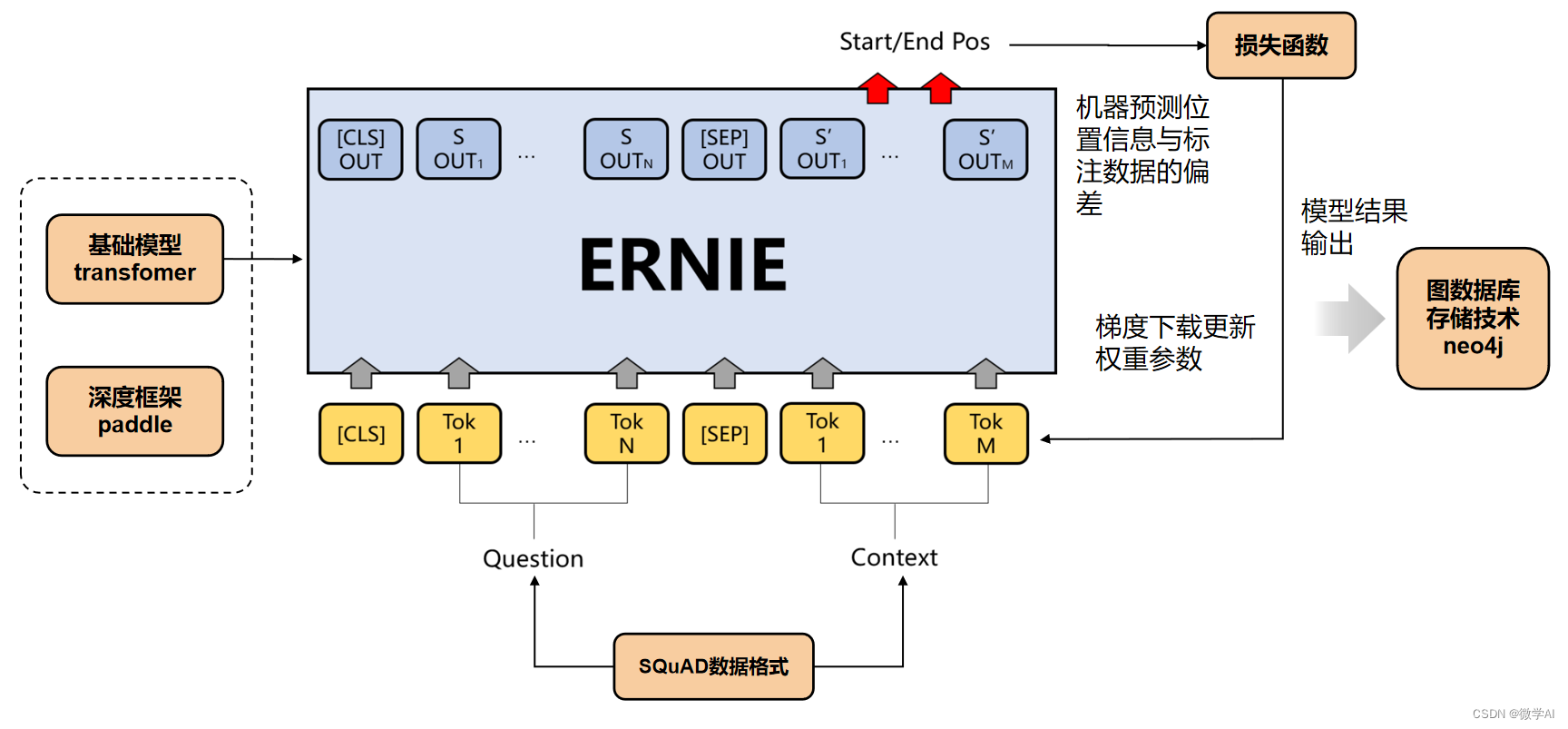
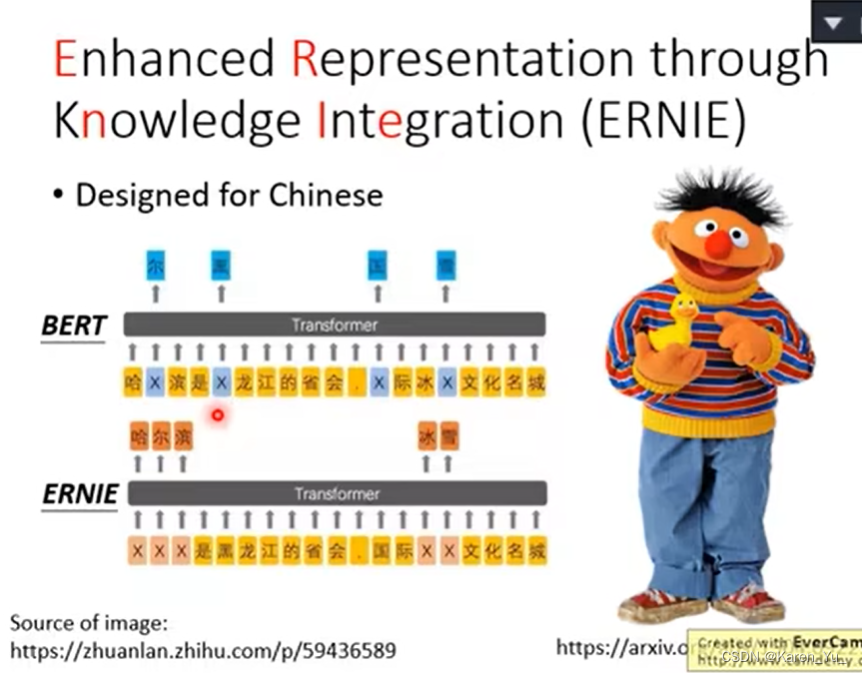
大模型的实践应用6-百度文心一言的基础模型ERNIE的详细介绍,与BERT模型的比较说明
大家好,我是微学AI,今天给大家讲一下大模型的实践应用6-百度文心一言的基础模型ERNIE的详细介绍,与BERT模型的比较说明。在大规模语料库上预先训练的BERT等神经语言表示模型可以很好地从纯文本中捕获丰富的语义模式,并通过微调的方式一致地提高各种NLP任务的性能。然而,现…

在 Google Colab 中微调用于命名实体识别的 BERT 模型
介绍 命名实体识别是自然语言处理(NLP)领域的一项主要任务。它用于检测文本中的实体,以便在下游任务中进一步使用,因为某些文本/单词对于给定上下文比其他文本/单词更具信息性和重要性。这就是 NER 有时被称为信息检索的原因,即从文本中提取相关关键词并将其分类为所需的类…
Attention——Transformer——Bert——FineTuning——Prompt
目录 一、Attention机制
二、Transformer模型
三、Bert模型
四、Fine-Tuning微调
五、Prompt 一、Attention机制
1、核心逻辑:从关注全部到关注重点;
2.计算attention公式: 3.优点:
(1)参数少&#…
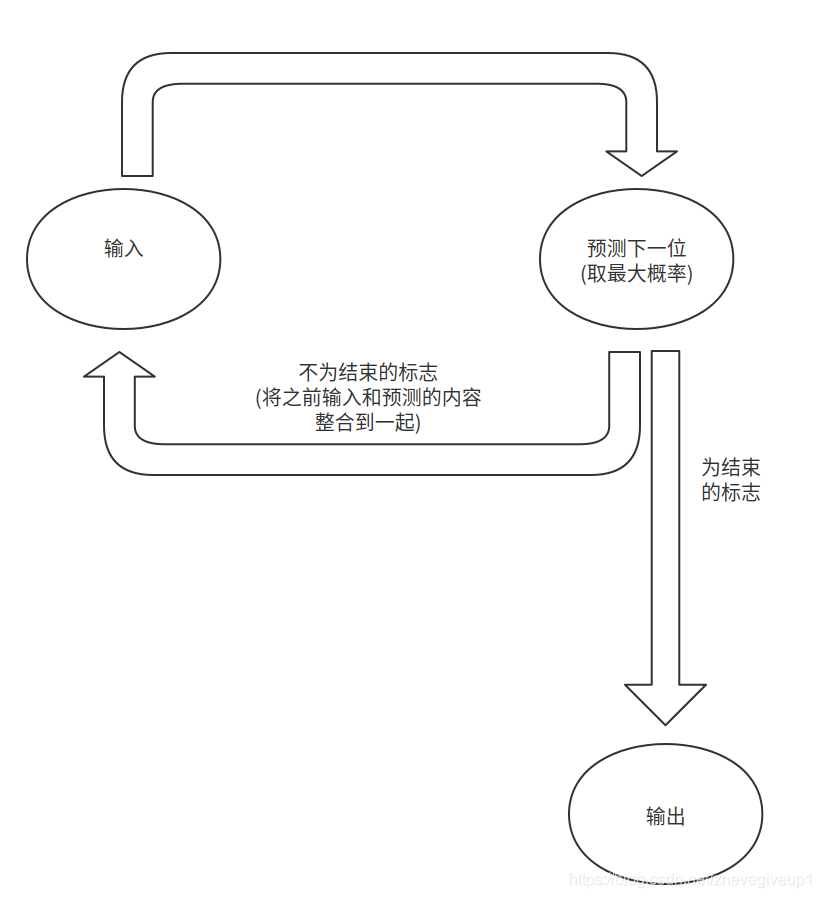
seq2seq bert模型训练以及预测过程讲解
seq2seq bert模型训练seq2seq训练模型的过程seq2seq预测模型的过程unilm代码部分讲解超出长度了是截取原始的部分还是截取摘要的部分???beam_search束搜索过程之中的batch问题seq2seq训练模型的过程
最近学习了seq2seq模型的内容,…
如何解决服务器显卡只在第一块运行的问题?
最近做实验,发现尽管使用了 import os os.environ[‘CUDA_VISIBLE_DEVICES’] ‘2’ 还是只用了第0块卡的问题 这里找到了答案,我们只需要再最前面就写这两行代码。 因为import torch之类的其他包或者依赖包可能回重置或者设定好而导致之后的设置不再生…

nlp bert 模型蒸馏大全和工具
1. 各种蒸馏方案大全 2. 蒸馏工具
https://github.com/airaria/TextBrewer#quickstart
2.1 蒸馏步骤: 2.2. 方法:看起来比较简单
import textbrewer
from textbrewer import GeneralDistiller
from textbrewer import TrainingConfig, DistillationCo…
【论文阅读】SKDBERT: Compressing BERT via Stochastic Knowledge Distillation
2022-2023年论文系列之模型轻量化和推理加速
定义最新
通过Connected Papers搜索引用PaBEE/DeeBERT/FastBERT的最新工作,涵盖: 模型推理加速边缘设备应用生成模型BERT模型知识蒸馏论文目录 SmartBERT: A Promotion of Dynamic Early Exiting Mechanism for Accelerating BE…
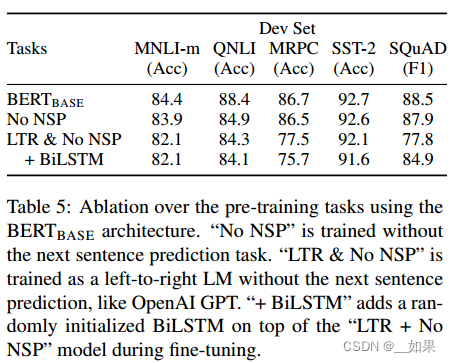
论文精读--BERT
不像视觉领域,在Bert出现之前的nlp领域还没有一个深的网络,使得能在大数据集上训练一个深的神经网络,并应用到很多nlp的任务上
Abstract We introduce a new language representation model called BERT, which stands for Bidirectional En…
人工智能Java SDK:基于BERT QA模型问答
Bert问答SDK
基于BERT QA模型,输入一个问题及包含答案的文本段落(最大长度384), 模型可以从文本段落中找到最佳的答案。 运行例子 - BertQaInferenceExample
问题:
When did Radio International start broadcasting?包含答案…
NLP-D7-李宏毅机器学习---X-AttentionGANBERTGPT
—0521今天4:30就起床了!真的是迫不及待想看新的课程!!! 昨天做人脸识别系统的demo查资料的时候,发现一个北理的大四做cv的同学,差距好大!!!我也要努力呀!&am…
BERT 上的动态量化(Beta)
BERT 上的动态量化(Beta)
简介
在本教程中,我们将动态量化应用在 BERT 模型上,紧跟 HuggingFace 转换器示例中的 BERT 模型。 通过这一循序渐进的旅程,我们将演示如何将著名的 BERT 等最新模型转换为动态量化模型。 …

bert层次位置编码
今天学习了bert之中的层次位置编码,感觉可以很好地用到maxlen超出512的部分苏神的层次位置编码 公式qi∗njαui(1−α)ujq_{i*nj} \alpha u_{i}(1-\alpha)u_{j}qi∗njαui(1−α)uj 这里的初始alpha最好设定为0.4,也就是说0~511的位置…
Intro project based on BERT
LeeMeng - 進擊的 BERT:NLP 界的巨人之力與遷移學習
这篇博客使用的是PyTorch,如果对PyTorch的使用比较陌生,建议直接去看PyTorch本身提供的tutorial,写的非常详细,还有很多例子。
这篇博客除了会介绍BERT之外&#…
![[NLP] BERT模型参数量](https://img-blog.csdnimg.cn/96ca3277f4164a19af8691a609e34b08.png)
[NLP] BERT模型参数量
一 BERT_Base 110M参数拆解 BERT_base模型的110M的参数具体是如何组成的呢,我们一起来计算一下:
刚好也能更深入地了解一下Transformer Encoder模型的架构细节。 借助transformers模块查看一下模型的架构:
import torch
from transformers …
基于 chinese-roberta-wwm-ext 微调训练中文命名实体识别任务
一、模型和数据集介绍
1.1 预训练模型
chinese-roberta-wwm-ext 是基于 RoBERTa 架构下开发,其中 wwm 代表 Whole Word Masking,即对整个词进行掩码处理,通过这种方式,模型能够更好地理解上下文和语义关联,提高中文文…
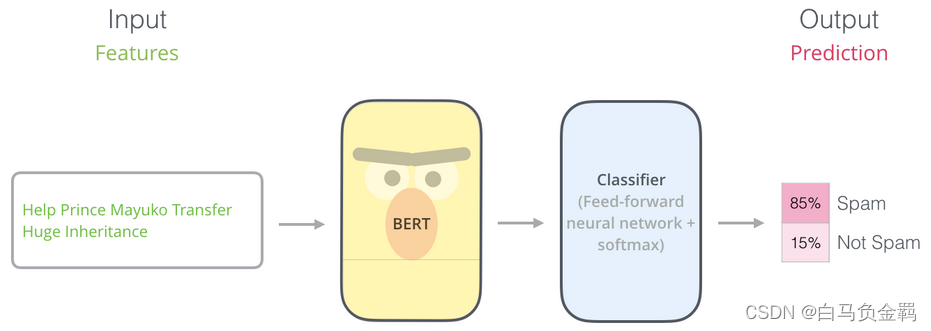
BERT(从理论到实践): Bidirectional Encoder Representations from Transformers【3】
这是本系列文章中的第3弹,请确保你已经读过并了解之前文章所讲的内容,因为对于已经解释过的概念或API,本文不会再赘述。
本文要利用BERT实现一个“垃圾邮件分类”的任务,这也是NLP中一个很常见的任务:Text Classification。我们的实验环境仍然是Python3+Tensorflow/Keras…
ChatGLM HuggingFace调用Bert词向量
开发环境推荐
GPU Dokcer
$ docker pull huggingface/transformers-pytorch-gpu:4.19.4CPU Dokcer
$ docker pull huggingface/transformers-pytorch-cpu:4.18.0 我这边使用的是CPU版本,建立容器
$ sudo docker run -it -d -v /Volumes/Yan_Errol/:/workspace --nam…
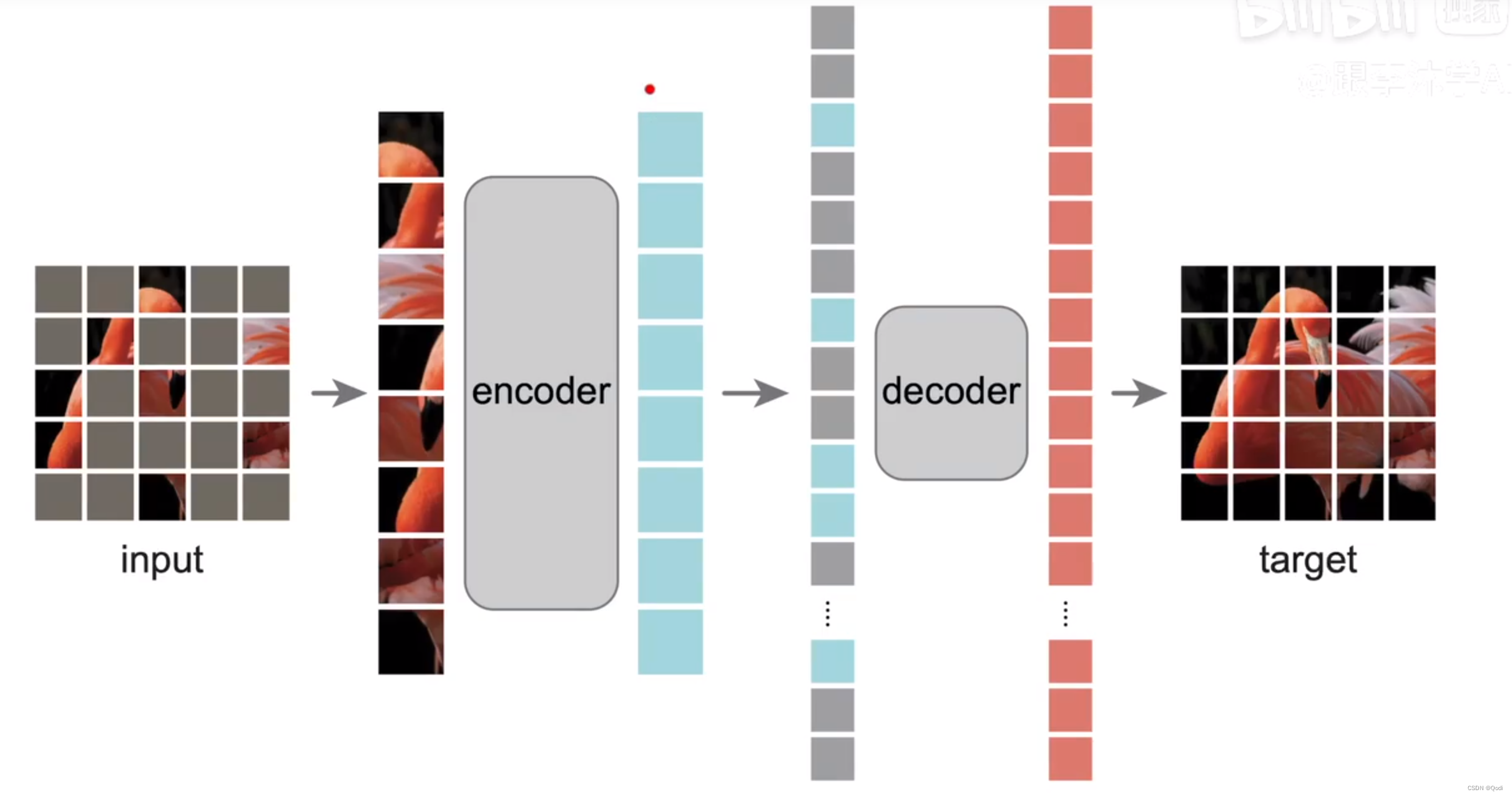
MAE 论文精读 | 在CV领域自监督的Bert思想
1. 背景
之前我们了解了VIT和transformer
MAE 是基于VIT的,不过像BERT探索了自监督学习在NLP领域的transformer架构的应用,MAE探索了自监督学习在CV的transformer的应用 论文标题中的Auto就是说标号来自于图片本身,暗示了这种无监督的学习 …
【学习草稿】bert文本分类
https://github.com/google-research/bert https://github.com/CyberZHG/keras-bert
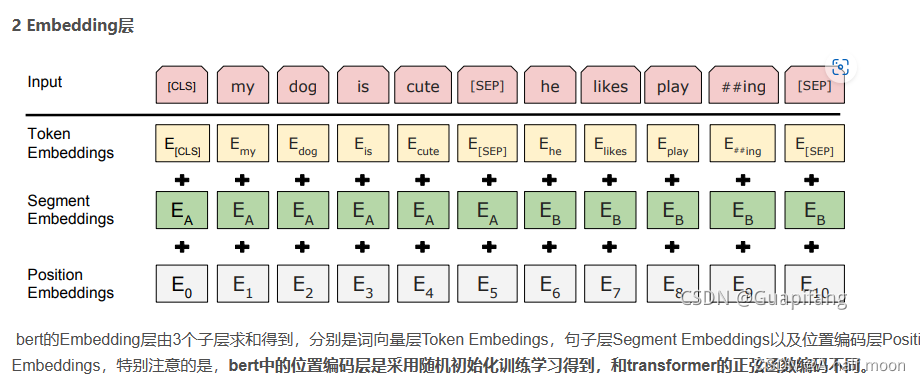
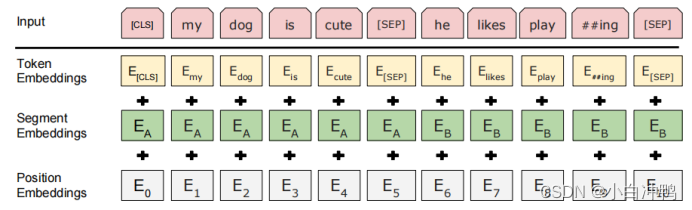
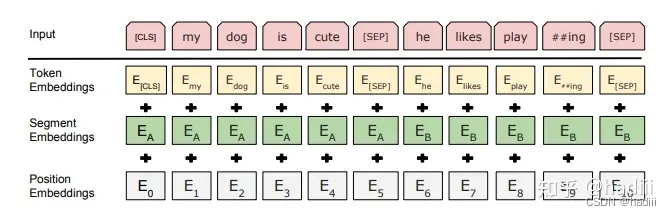
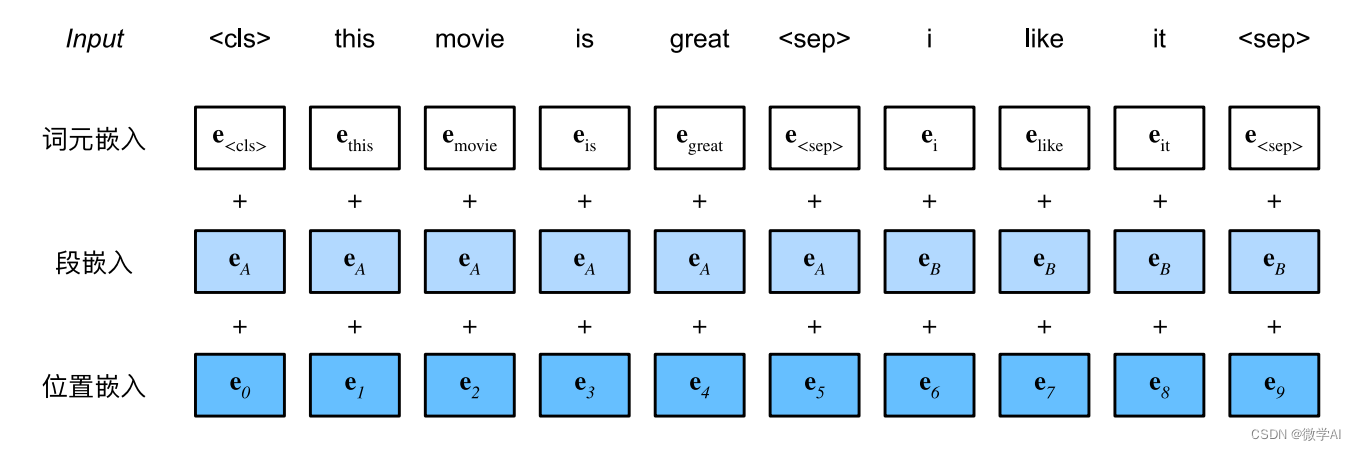
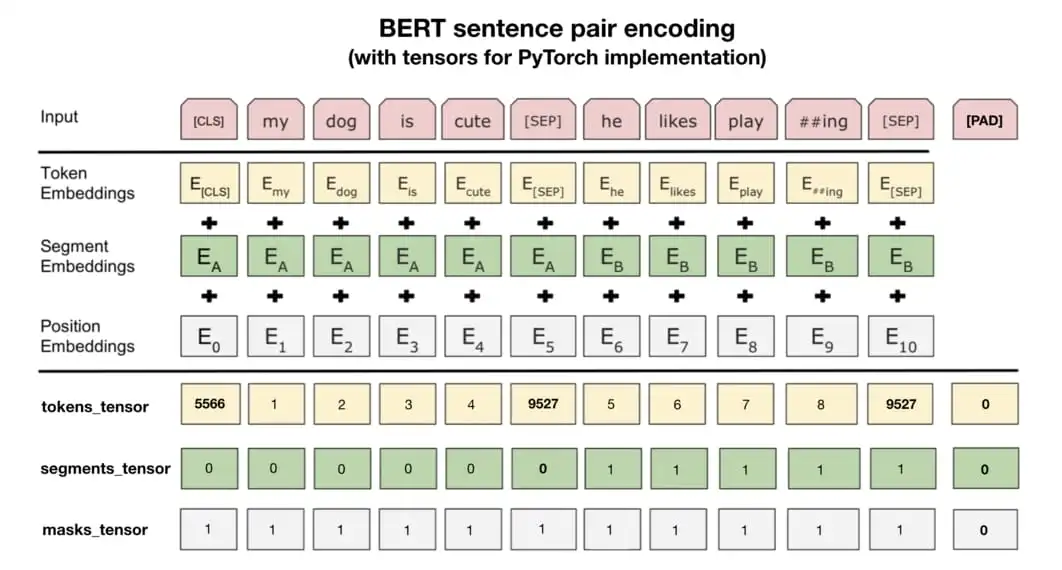
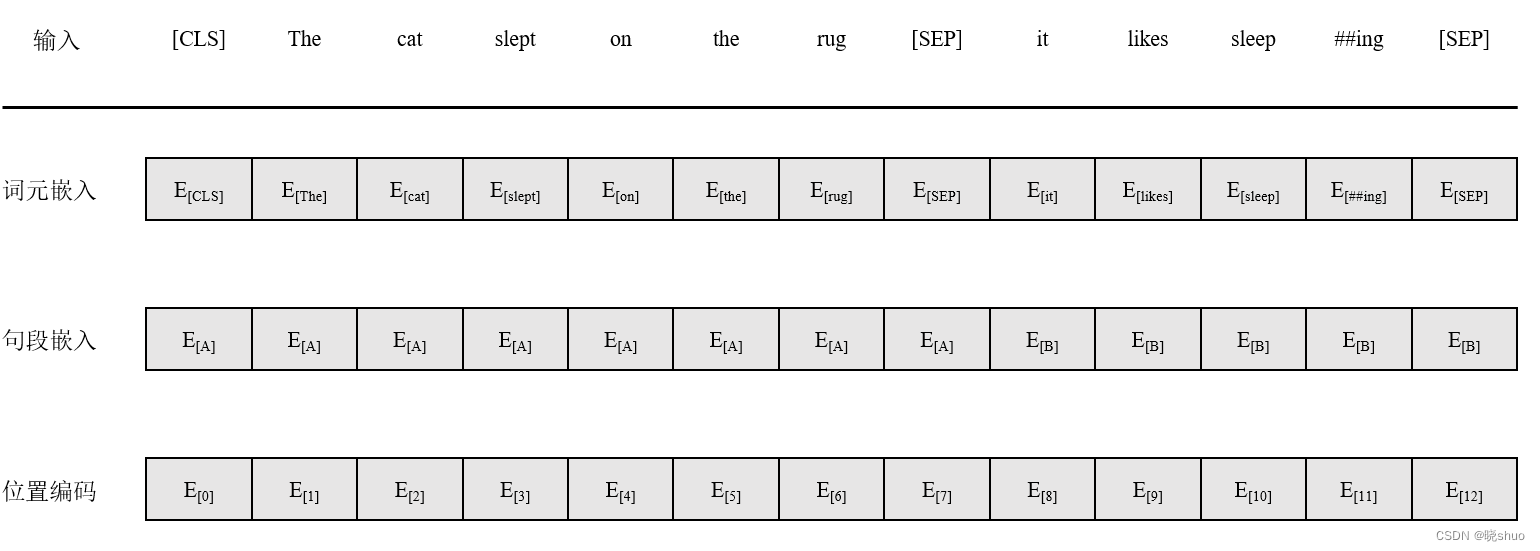
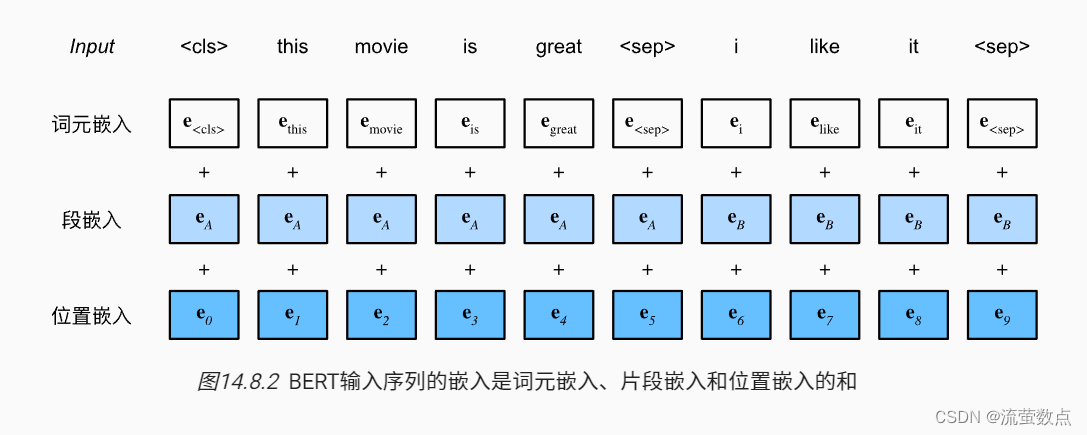
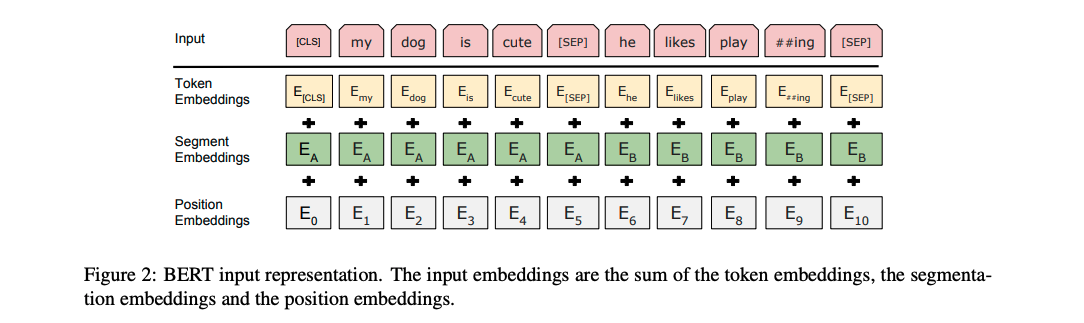
在 BERT 中,每个单词的嵌入向量由三部分组成:
Token 嵌入向量:该向量是 WordPiece 分词算法得到的子单词 ID 对应的嵌入向量。
Segment 嵌入向量&#x…
bert其他内容个人记录
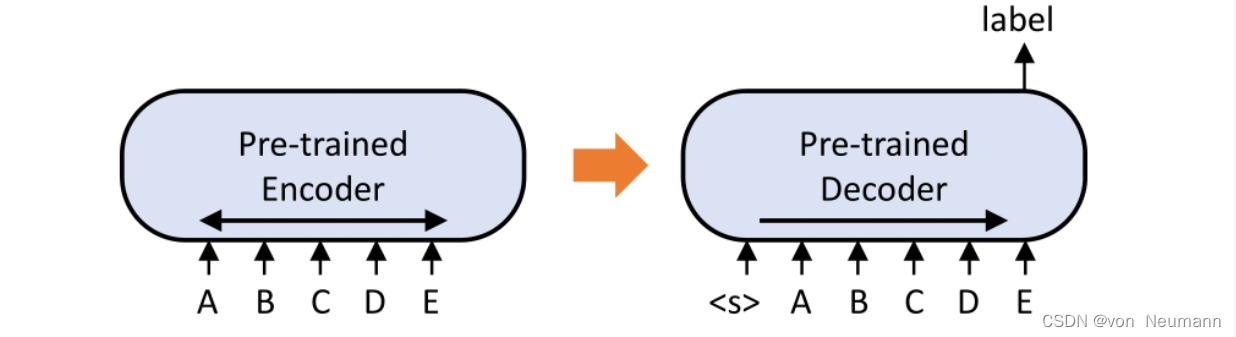
Pre-training a seq2seq model
BERT只是一个预训练Encoder,有没有办法预训练Seq2Seq模型的Decoder?
在一个transformer的模型中,将输入的序列损坏,然后Decoder输出句子被破坏前的结果,训练这个模型实际上是预训练一个…
使用无标注的数据训练Bert
文章目录 1、准备用于训练的数据集2、处理数据集3、克隆代码4、运行代码5、将ckpt模型转为bin模型使其可在pytorch中运用 Bert官方仓库:https://github.com/google-research/bert
1、准备用于训练的数据集
此处准备的是BBC news的数据集,下载链接&…
BERT 模型是什么
科学突破很少发生在真空中。相反,它们往往是建立在积累的人类知识之上的阶梯的倒数第二步。要了解 ChatGPT 和 Google Bart 等大型语言模型 (LLM) 的成功,我们需要回到过去并谈论 BERT。
BERT 由 Google 研究人员于 2018 年开发&…
大语言模型系列-BERT
文章目录 前言一、BERT的网络结构和流程1.网络结构2.输入3.输出4.预训练Masked Language ModelNext Sentence Predictionloss 二、BERT创新点总结 前言
前文提到的GPT-1开创性的将Transformer Decoder架构引入NLP任务,并明确了预训练(学习 text 表征&am…

BART论文解读:BERT和GPT结合起来会发生什么?
BART:Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension
主要工作 提出了BART (Bidirectional and Auto-Regressive Transformers), 是一种用于自然语言生成、翻译和理解的序列到序列的预训练方法。它…
【HuggingFace文档学习】Bert的token分类与句分类
BERT特性:
BERT的嵌入是位置绝对(position absolute)的。BERT擅长于预测掩码token和NLU,但是不擅长下一文本生成。
1.BertForTokenClassification
一个用于token级分类的模型,可用于命名实体识别(NER)、部分语音标记…
机器学习、深度学习、时序 相关 技术知识
创建于:2022.05.27 更新于:2022.05.27, 2022.07.25 文章目录1、优秀资源2、机器学习3、时序资料4、深度学习 for NLP4.1 词向量4.2 BERT预训练模型4.3 语义相似度4.4 条件随机场4.5 深度学习相关问题5、样本不均衡6、数据增强1、优秀资源 标点符 博客 Ro…
BERT-pytorch源码实现,解决内存溢出问题
BERT-pytorch源码实现,解决内存溢出问题
相信大家很多人都在做BERT这个模型,但是,有些人可能就是直接从transfermer这个模型里直接导入数据,但是这种方法不方便我们修改模型,于是有些人就通过pytorch详细实现了BERT,但…
2022最新版-李宏毅机器学习深度学习课程-P51 BERT的各种变体
之前讲的是如何进行fine-tune,现在讲解如何进行pre-train,如何得到一个pre train好的模型。
CoVe 其实最早的跟预训练有关的模型,应该是CoVe,是一个基于翻译任务的一个模型,其用encoder的模块做预训练。
但是CoVe需要…

代码笔记 | bert-event-extraction
文章目录1 数据处理1.1 数据集1.2 预处理1.2.1 数据加载1.2.2 utiles2 模型2.1 触发词预测2.2 论元预测3 训练4 评测代码链接:https://github.com/nlpcl-lab/bert-event-extraction1 数据处理
1.1 数据集
数据集使用ACE 2005英文序列,数据集的解析过程…
[算法前沿]--026-如何实现一个BERT
前言
本文包含大量源码和讲解,通过段落和横线分割了各个模块,同时网站配备了侧边栏,帮助大家在各个小节中快速跳转,希望大家阅读完能对BERT有深刻的了解。同时建议通过pycharm、vscode等工具对bert源码进行单步调试,调试到对应的模块再对比看本章节的讲解。
涉及到的jup…
BERT变体(1):ALBERT、RoBERTa、ELECTRA、SpanBERT
Author:龙箬 Computer Application Technology Change the World with Data and Artificial Intelligence ! CSDNweixin_43975035 *天下之大,虽离家万里,何处不可往!何事不可为! 1. ALBERT \qquad ALBERT的英文全称为A Lite versi…
自然语言处理的bert, GPT, GPT-2, transformer, ELMo, attention机制都是些何方神圣???
2018年是NLP领域巨变的一年,这个好像我们都知道,但是究竟是哪里剧变了,哪里突破了?经常听大佬们若无其事地抛出一些高级的概念,你却插不上嘴,隐隐约约知道有这么个东西,刚要开口:噢&…

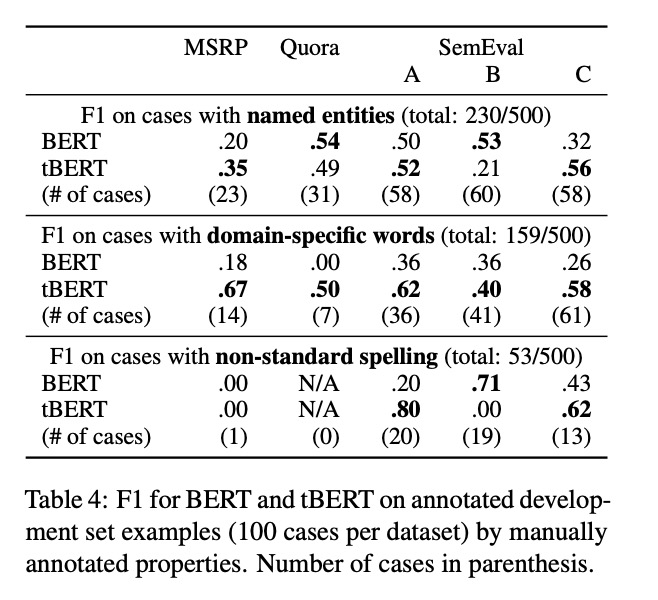
tBERT-BERT融合主题模型
今天分享一个论文ACL2020-tBERT,论文主要融合主题模型和BERT去做语义相似度判定,在特定领域使用这个模型,效果更明显。
掌握以下几点:
【CLS】向量拼接两个句子各自的主题模型,效果有提升尤其是在特定领域的数据集合…

NLP(六十八)使用Optimum进行模型量化
本文将会介绍如何使用HuggingFace的Optimum,来对微调后的BERT模型进行量化(Quantization)。 在文章NLP(六十七)BERT模型训练后动态量化(PTDQ)中,我们使用PyTorch自带的PTDQ&…

BERT(从理论到实践): Bidirectional Encoder Representations from Transformers【1】
预训练模型:A pre-trained model is a saved network that was previously trained on a large dataset, typically on a large-scale image-classification task. You either use the pretrained model as is or use transfer learning to customize this model to a given t…
【深度学习】语言模型与注意力机制以及Bert实战指引之一
文章目录 统计语言模型和神经网络语言模型注意力机制和Bert实战Bert配置环境和模型转换格式准备 模型构建网络设计模型配置代码实战 统计语言模型和神经网络语言模型
区别:统计语言模型的本质是基于词与词共现频次的统计,而神经网络语言模型则是给每个词…
pytorch bert实现文本分类
以imdb公开数据集为例,bert模型可以在huggingface上自行挑选
1.导入必要的库
import os
import torch
from torch.utils.data import DataLoader, TensorDataset, random_split
from transformers import BertTokenizer, BertModel, BertConfig
from torch import…
基于bert-base-chinese的二分类任务
使用hugging-face中的预训练语言模型bert-base-chinese来完成二分类任务,整体流程为: 1.定义数据集 2.加载词表和分词器 3.加载预训练模型 4.定义下游任务模型 5.训练下游任务模型 6.测试
具体代码如下:
1.定义数据集
import torch
from d…
Python - Bert-VITS2 语音推理服务部署
目录
一.引言
二.服务搭建
1.服务配置
2.服务代码
3.服务踩坑
三.服务使用
1.服务启动
2.服务调用
3.服务结果
四.总结 一.引言
上一篇文章我们介绍了如果使用 conda 搭建 Bert-VITS2 最新版本的环境并训练自定义语音,通过 1000 个 epoch 的训练…
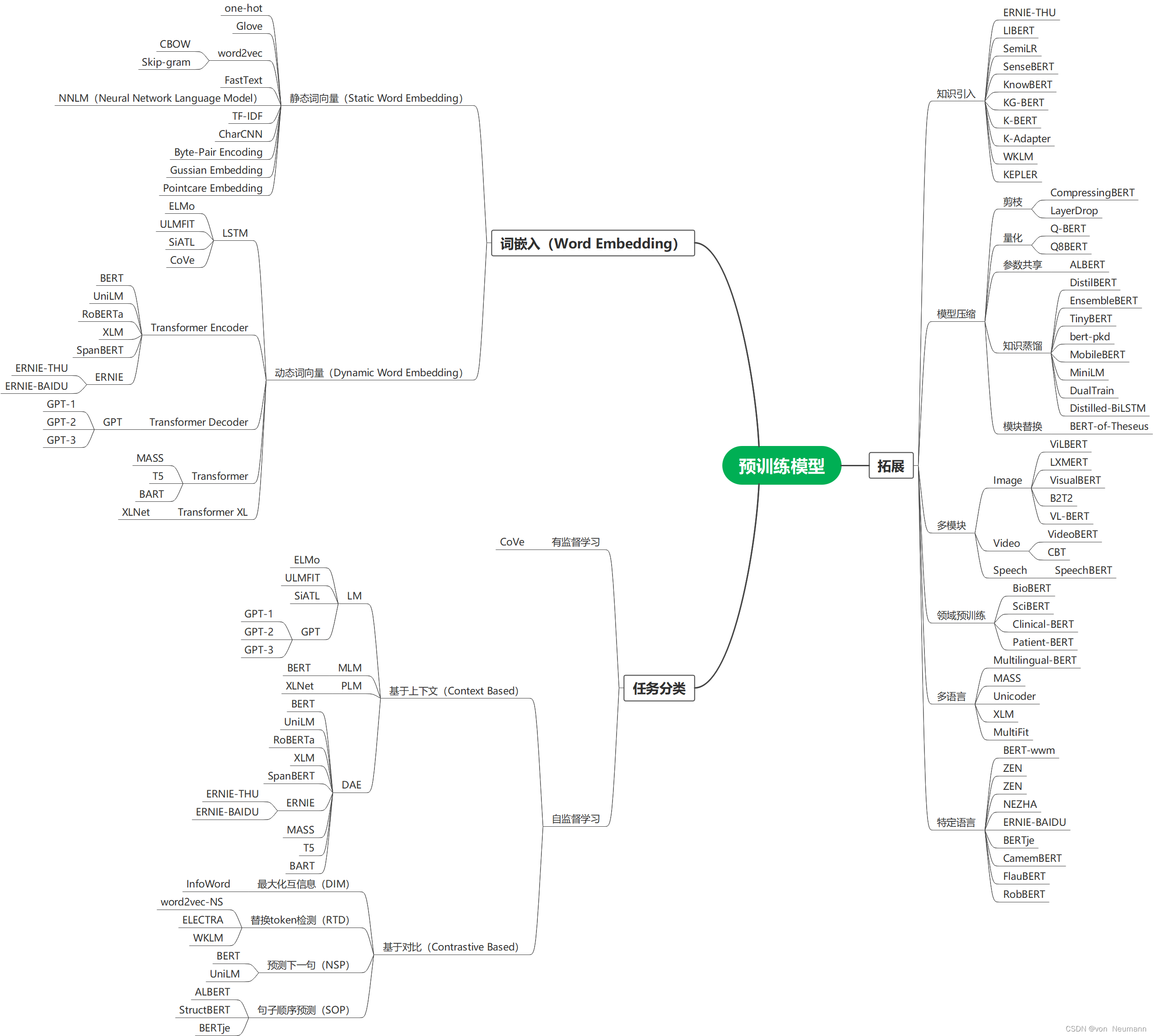
自然语言处理从入门到应用——预训练模型总览:两大任务类型
分类目录:《自然语言处理从入门到应用》总目录 相关文章: 预训练模型总览:从宏观视角了解预训练模型 预训练模型总览:词嵌入的两大范式 预训练模型总览:两大任务类型 预训练模型总览:预训练模型的拓展 …

文献阅读:Should You Mask 15% in Masked Language Modeling?
文献阅读:Should You Mask 15% in Masked Language Modeling? 1. 内容简介2. 实验考察 1. mask比例考察2. corruption & prediction3. 80-10-10原则考察4. mask选择考察 3. 结论 & 思考 文献链接:https://arxiv.org/pdf/2202.08005.pdf
1. 内…
自然语言处理实战项目20-一看就懂的BERT模型介绍,指导大家对BERT下游任务改造的实际应用
大家好,我是微学AI,今天给大家介绍一下自然语言处理实战项目20-通俗易懂的BERT模型介绍,指导大家对BERT下游任务改造的应用,BERT模型是一种用于自然语言处理的深度学习模型,它可以通过训练来理解单词之间的上下文关系,从而为下游任务提供高质量的语言表示。它的结构是由多…
gpt1与bert区别
区别1:网络结构(主要是Masked Multi-Head-Attention和Multi-Head-Attention)
gpt1使用transformer的decoder,单向编码,是一种基于语言模型的生成式模型,更适合生成下一个单词或句子 bert使用transformer的…

BERT(NAACL 2019)-NLP预训练大模型论文解读
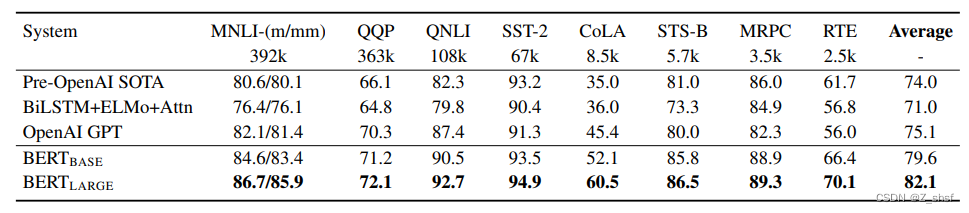
文章目录摘要算法BERT预训练Masked LMNSPFine-tune BERT实验GLUESQuAD v1.1SQuAD v2.0SWAG消融实验预训练任务影响模型大小影响BERT基于特征的方法结论论文:
《BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding》githubÿ…


王树森《RNN Transformer》系列公开课
本课程主要介绍NLP相关,包括RNN、LSTM、Attention、Transformer、BERT等模型,以及情感识别、文本生成、机器翻译等应用
ShusenWang的个人空间-ShusenWang个人主页-哔哩哔哩视频 (bilibili.com) (一)NLP基础
1、数据处理基础
数…
Bert预训练模型的使用
1.下载预训练模型
pytorch_bin文件:
‘bert-base-uncased’: “https://s3.amazonaws.com/models.huggingface.co/bert/bert-base-uncased.tar.gz”, ‘bert-large-uncased’: “https://s3.amazonaws.com/models.huggingface.co/bert/bert-large-uncased.tar.gz”, ‘bert-b…
bert简单介绍和实践
bert模型是Google在2018年10月发布的语言表示模型,在NLP领域横扫了11项任务的最优结果,可以说是现今最近NLP中最重要的突破。Bert模型的全称是Bidirectional Encoder Representations from Transformers,是通过训练Masked Language Model和预…
bert-base-chinese 判断上下句
利用BERT等模型来实现语义分割。BERT等模型在预训练的时候采用了NSP(next sentence prediction)的训练任务,因此BERT完全可以判断两个句子(段落)是否具有语义衔接关系。这里我们可以设置相似度阈值 MERGE_RATIO &#…
使用 Hugging Face Transformer 创建 BERT 嵌入
介绍 最初是为了将文本从一种语言更改为另一种语言而创建的。BERT 极大地影响了我们学习和使用人类语言的方式。它改进了原始 Transformer 模型中理解文本的部分。创建 BERT 嵌入尤其擅长抓取具有复杂含义的句子。它通过检查整个句子并理解单词如何连接来做到这一点。Hugging F…

Using Prior Knowledge to Guide BERT’s Attention in Semantic Textual Matching Tasks论文解读
一、总结 二、其他
代码:https://github.com/xiatingyu/Bert_sim
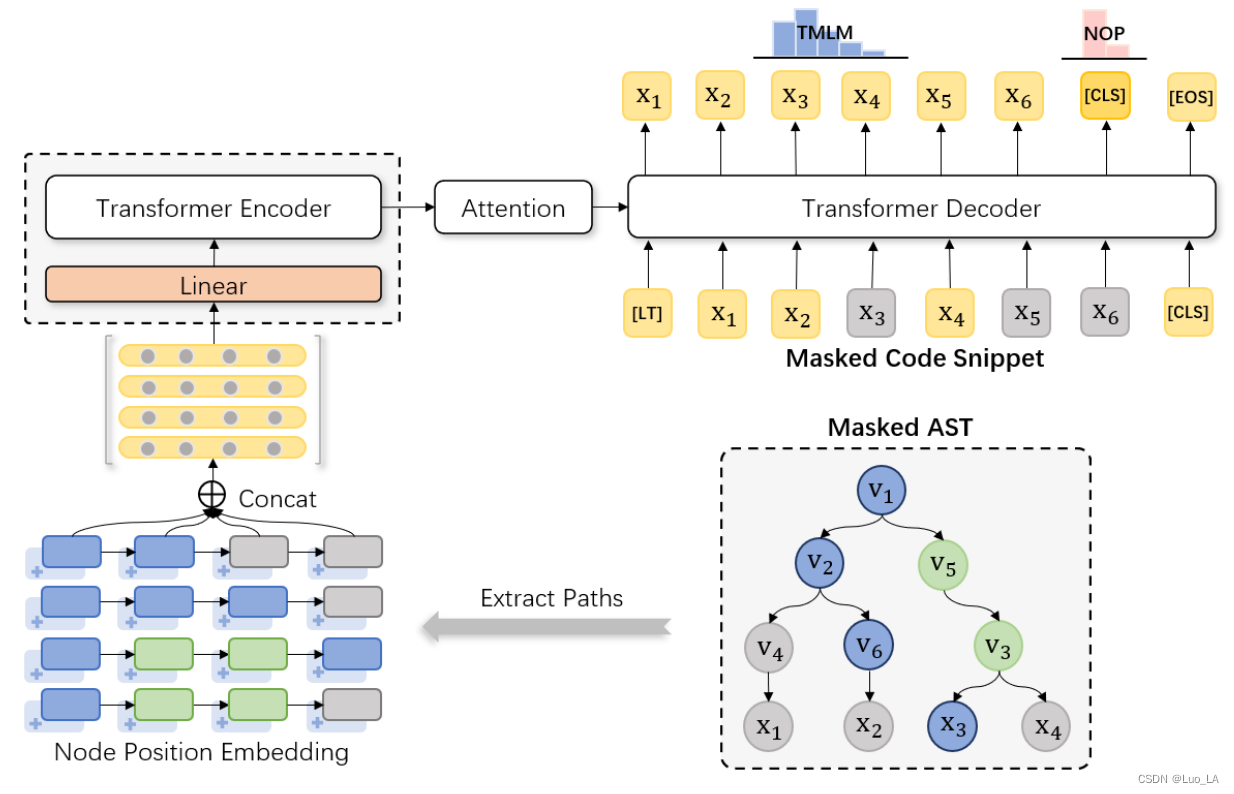
TreeBERT:基于树的编程语言预训练模型。
TreeBERT
https://arxiv.org/abs/2105.12485
Comments: Accepted by UAI2021 Subjects: Machine Learning (cs.LG); Programming Languages (cs.PL) Cite as: arXiv:2105.12485 [cs.LG]
1 Introduction
现有挑战: 设计适当的机制来学习程序的语法结构 代码是强结…
自然语言处理---Transformer机制详解之BERT GPT ELMo模型的对比
1 BERT、GPT、ELMo的不同点 关于特征提取器: ELMo采用两部分双层双向LSTM进行特征提取, 然后再进行特征拼接来融合语义信息.GPT和BERT采用Transformer进行特征提取.很多NLP任务表明Transformer的特征提取能力强于LSTM, 对于ELMo而言, 采用1层静态token embedding 2层LSTM, 提取…
BERT 快速理解——思路简单描述
定义:
BERT(Bidirectional Encoder Representations from Transformers)是一种预训练的语言模型,它基于Transformer架构,通过在大规模的未标记文本上进行训练来学习通用的语言表示。
输入
在BERT中,输入…

BERT句向量(一):Sentence-BERT
前言
句向量:能够表征整个句子语义的向量,目前效果比较好的方法还是通过bert模型结构来实现,也是本文的主题。
有了句向量,我们可以用来进行聚类,处理大规模的文本相似度比较,或者基于语义搜索的信息检索…
深入理解深度学习——BERT(Bidirectional Encoder Representations from Transformers):NSP任务
分类目录:《深入理解深度学习》总目录 相关文章: BERT(Bidirectional Encoder Representations from Transformers):基础知识 BERT(Bidirectional Encoder Representations from Transformers)…
Bert Pytorch 源码分析:二、注意力层
# 注意力机制的具体模块
# 兼容单头和多头
class Attention(nn.Module):"""Compute Scaled Dot Product Attention"""# QKV 尺寸都是 BS * ML * ES# (或者多头情况下是 BS * HC * ML * HS,最后两维之外的维度不重要&#…
Bert如何融入知识一-百度和清华ERINE
Bert如何融入知识(一)-百度和清华ERINE
首先想一下Bert是如何训练的?首先我获取无监督语料,随机mask掉一部分数据,去预测这部分信息。
这个过程其实和W2C很类似,上下文相似的情况下,mask掉的单词的词向量很可能非常相…
如何快速部署本地训练的 Bert-VITS2 语音模型到 Hugging Face
Hugging Face是一个机器学习(ML)和数据科学平台和社区,帮助用户构建、部署和训练机器学习模型。它提供基础设施,用于在实时应用中演示、运行和部署人工智能(AI)。用户还可以浏览其他用户上传的模型和数据集…
加载Bert预训练模型时报错:huggingface_hub.utils._validators.HFValidationError
具体报错情况如下: huggingface_hub.utils._validators.HFValidationError: Repo id must be in the form repo_name or namespace/repo_name: ./bert/bert_base_cased_ICEWS14. Userepo_typeargument if needed.
很简单,我download下来的代码没有并没有…
自然语言处理实战项目25-T5模型和BERT模型的应用场景以及对比研究、问题解答
大家好,我是微学AI,今天给大家介绍一下自然语言处理实战项目25-T5模型和BERT模型的应用场景以及对比研究、问题解答。T5模型和BERT模型是两种常用的自然语言处理模型。T5是一种序列到序列模型,可以处理各种NLP任务,而BERT主要用于预训练语言表示。T5使用了类似于BERT的预训…
Transformer 的双向编码器表示 (BERT)
一、说明 本文介绍语言句法中,最可能的单词填空在self-attention的表现形式,以及内部原理的介绍。 二、关于本文概述 在我之前的博客中,我们研究了关于生成式预训练 Transformer 的完整概述,关于生成式预训练 Transformer (GPT) 的…

读书笔记:多Transformer的双向编码器表示法(Bert)-1
多Transformer的双向编码器表示法
Bidirectional Encoder Representations from Transformers,即Bert; 本笔记主要是对谷歌Bert架构的入门学习:
介绍Transformer架构,理解编码器和解码器的工作原理;掌握Bert模型架构…
![[oneAPI] 使用Bert进行中文文本分类](https://img-blog.csdnimg.cn/954489c13cf6423da5b0f326093cff84.png)
[oneAPI] 使用Bert进行中文文本分类
[oneAPI] 使用Bert进行中文文本分类 基于BERT的文本分类模型数据预处理数据集定义tokenize建立词表转换为Token序列padding处理与mask 模型 结果OneAPI参考资料 比赛:https://marketing.csdn.net/p/f3e44fbfe46c465f4d9d6c23e38e0517 Intel DevCloud for oneAPI&…
Bert下载和使用(以bert-base-uncased为例)
Bert官方github地址:https://github.com/google-research/bert?tabreadme-ov-file 【hugging face无法加载预训练模型】OSError:Can‘t load config for ‘./bert-base-uncased‘. If you‘re trying 如何下载和在本地使用Bert预训练模型 以bert-base-u…
【CCF BDCI 2023】多模态多方对话场景下的发言人识别 Baseline 0.71 NLP 部分
【CCF BDCI 2023】多模态多方对话场景下的发言人识别 Baseline 0.71 NLP 部分 概述NLP 简介文本处理词嵌入上下文理解 文本数据加载to_device 函数构造数据加载样本数量 len获取样本 getitem 分词构造函数调用函数轮次嵌入 RobertaRoberta 创新点NSP (Next Sentence Prediction…
BERT: Pre-training of Deep Bidirectional Transformers forLanguage Understanding
参考BERT原文[1810.04805] BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding (arxiv.org)【(强推)李宏毅2021/2022春机器学习课程】 https://www.bilibili.com/video/BV1Wv411h7kN/?p73&share_sourcecopy_web&vd_source30e93e9c70e…
BERT系列预训练模型资料
创建于:20220521 修改于:20220521 文章目录NLP中的预训练语言模型(一)—— ERNIE们和BERT-wwm
NLP中的预训练语言模型(二)—— Facebook的SpanBERT和RoBERTa
XL-Net和Transformer-XL
NLP中的预训练语言模…
BERT原理Fine TuningBert变种
文章目录 BERT原理训练时的任务任务一任务二任务二的改进 模型的输入 BERT - Fine Tuning单个句子的预测类序列标注类Q&A类seq2seq? BERT 变种Transformer-XLXLNetAutoregressive Language ModelDenoising Auto-Encoder乱序Two-Stream Attention与Transformer-X…
BERT:来自 Transformers 的双向编码器表示 – 释放深度上下文化词嵌入的力量
BERT是Transformers 双向编码器表示的缩写,是 2018 年推出的改变游戏规则的 NLP 模型之一。BERT 的情感分类、文本摘要和问答功能使其看起来像是一站式 NLP 模型。尽管更新和更大的语言模型已经出现,但 BERT 仍然具有相关性,并且值得学习它的架构、方法和功能。 这篇综合文…
【从零开始实现意图识别】中文对话意图识别详解
前言
意图识别(Intent Recognition)是自然语言处理(NLP)中的一个重要任务,它旨在确定用户输入的语句中所表达的意图或目的。简单来说,意图识别就是对用户的话语进行语义理解,以便更好地回答用户…
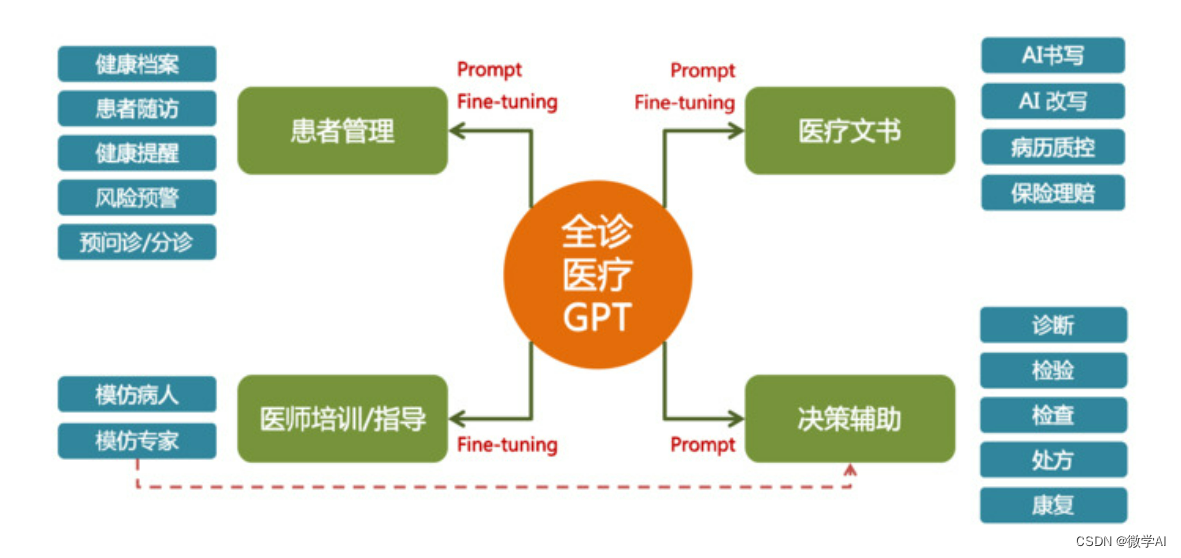
大模型的实践应用2-基于BERT模型训练医疗智能诊断问答的运用研究,协助医生进行疾病诊断
大家好,我是微学AI,今天给大家介绍一下大模型的实践应用2-基于BERT模型训练医疗智能诊断问答的运用研究,协助医生进行疾病诊断。医疗大模型通过收集和分析大量的医学数据和临床信息,能够协助医生进行疾病诊断、制定治疗方案和评估预后等任务。利用医疗大模型,可以帮助医生…
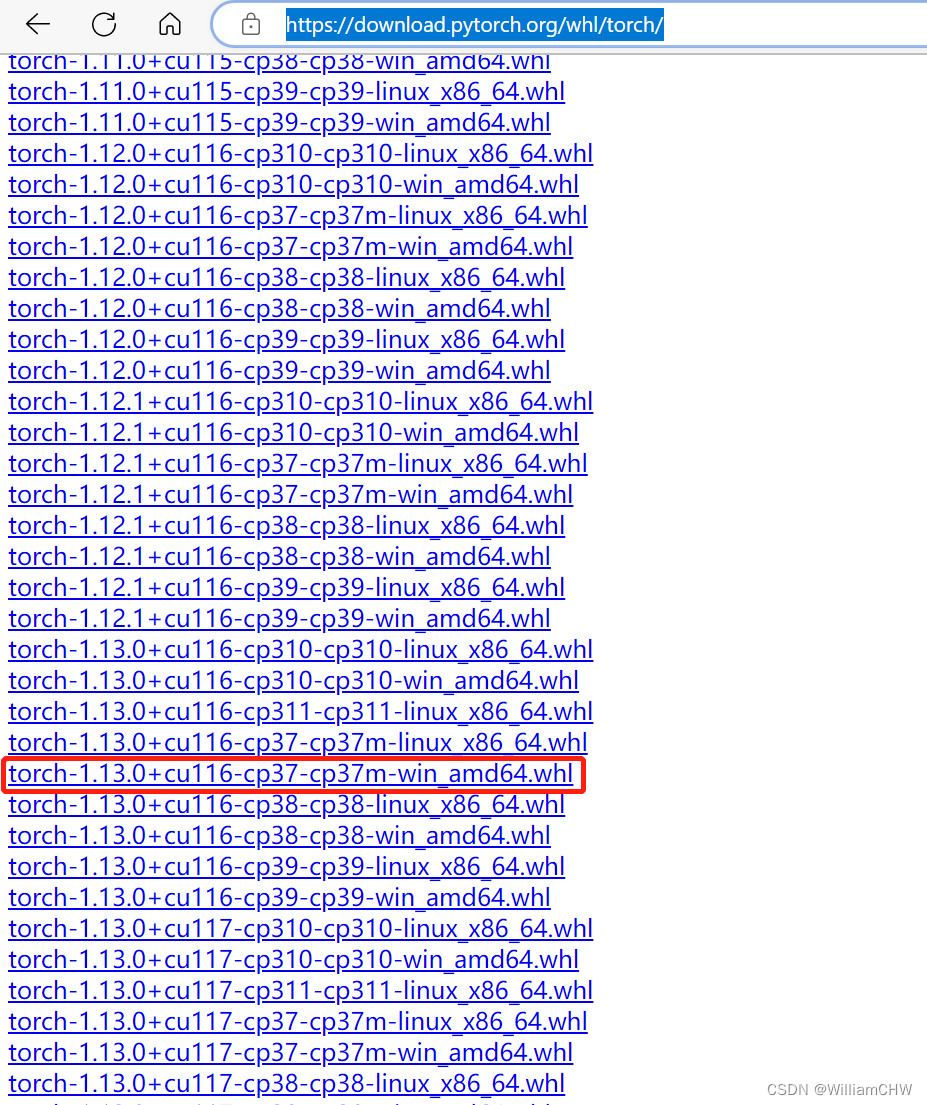
bert 环境搭建之PytorchTransformer 安装
这两天跑以前的bert项目发现突然跑不了,报错信息如下:
Step1 transformer 安装
RuntimeError: Failed to import transformers.models.bert.modeling_bert because of the following error (look up to see its traceback): module signal has no att…


BERT模型蒸馏完全指南(原理技巧代码)
BERT模型蒸馏完全指南(原理/技巧/代码)
小朋友,关于模型蒸馏,你是否有很多问号: 蒸馏是什么?怎么蒸BERT?BERT蒸馏有什么技巧?如何调参?蒸馏代码怎么写?有现成的吗?今天rumor就结合Distilled BiLSTM/BERT-PKD/DistillBERT/TinyBERT/MobileBERT/MiniLM六大经典模型,…
深度学习自然语言处理(NLP)模型BERT:从理论到Pytorch实战
文章目录 深度学习自然语言处理(NLP)模型BERT:从理论到Pytorch实战一、引言传统NLP技术概览规则和模式匹配基于统计的方法词嵌入和分布式表示循环神经网络(RNN)与长短时记忆网络(LSTM)Transform…


一个基于Bert的情感分类
1. 问题描述 题目来自于DataFountain上的“疫情期间网民情绪识别”的挑战赛,最终AUC达到了0.734,取得Top5%的成绩。主要内容是分析疫情期间的用户微博极性(分为消极:-1、中性:0、积极:1三种)。本文主要是对数据进行一定分析并做一个以该数据为基础的bert实战记录。
2. …
NLP-D45-nlp比赛D14文献阅读标签mac-bert时间大局观
—0357今天3点半就自然醒了,做梦梦到的都是论文、模型之类的omg 希望今天可以目标导向,提高效率。
文献阅读
1、引用标签 引言背景(直接引用) 句型(值得学习的句型或词汇) 可引用(硬核的知识文…
BERT(从理论到实践): Bidirectional Encoder Representations from Transformers【2】
这是本系列文章中的第二弹,假设你已经读过了前文。先来简单回顾一下BERT的想法:
1)在Word2Vec【1】中,每个单词生成的Embedding是固定的。但这就带来了一个显而易见的问题:同一个单词在不同上下文中的意思是不同的。例如mouse,可以是鼠标的意思,也可以是老鼠的意思。但…
使用 Hugging Face Transformer 微调 BERT
微调 BERT有助于将其语言理解能力扩展到更新的文本领域。BERT 的与众不同之处在于它能够掌握句子的上下文关系,理解每个单词相对于其邻居的含义。我们将使用 Hugging Face Transformers 训练 BERT,还将教 BERT 分析 Arxiv 的摘要并将其分类为 11 个类别之一。 为什么微调 BER…
【BERT】深入BERT模型2——模型中的重点内容,两个任务
前言
BERT出自论文:《BERT:Pre-training of Deep Bidirectional Transformers for Language Understanding》 2019年
近年来,在自然语言处理领域,BERT模型受到了极为广泛的关注,很多模型中都用到了BERT-base或者是BE…

多模态基础---BERT
1. BERT简介
BERT用于将一个输入的句子转换为word_embedding,本质上是一个transformer的Encoder。
1.1 BERT的两种训练方法
预测被遮挡的单词预测两个句子是否是相邻的句子 1和2是同时训练的
1.1 BERT的四种用法
预测句子的类别:输入一个句子&…
Bert-VITS2本地部署遇到的错误
关于Bert-VITS2本地部署遇到的错误
1、在下载python中相关依赖时报错
building ‘hdbscan._hdbscan_tree’ extension error: Microsoft Visual C 14.0 or greater is required. Get it with “Microsoft C Build Tools”: https://visualstudio.microsoft.com/visual-cpp-bu…
计算机网络--第一次作业
1、比较电路交换、报文交换和分组报文交换优缺点 电路交换 电路交换是以电路连接为目的的交换方式,通信之前要在通信双方之间建立一条被双方独占的物理通道(由通信双方之间的交换设备和链路逐段连接而成)。 优点: ①由于通信线路为…

使用 BERT 进行文本分类 (02/3)
一、说明 在使用BERT(1)进行文本分类中,我向您展示了一个BERT如何标记文本的示例。在下面的文章中,让我们更深入地研究是否可以使用 BERT 来预测文本是使用 PyTorch 传达积极还是消极的情绪。首先,我们需要准备数据…

为什么BERT有效【综述】
论文标题:A Primer in BERTology: What We Know About How BERT Works 论文地址:https://arxiv.org/pdf/2002.12327.pdf 摘要 BERT学习了什么类型的信息是如何表示的对其训练目标和体系结构的常见修改过度参数化问题和压缩方法未来研究的方向1 导言 Tran…

BERT 蒸馏在垃圾舆情识别中的探索【文章学习】
一、总结
原文:BERT 蒸馏在垃圾舆情识别中的探索:https://mp.weixin.qq.com/s/ljYPSK20ce9EoPbfGlaCrw
二、其他资料
Distilling Task-Specific Knowledge from BERT into Simple Neural Networks论文学习:https://blog.csdn.net/qq_1694…
![[oneAPI] 基于BERT预训练模型的命名体识别任务](https://img-blog.csdnimg.cn/751af0a1b40945bebb9db0b22c44d44a.png)
[oneAPI] 基于BERT预训练模型的命名体识别任务
[oneAPI] 基于BERT预训练模型的命名体识别任务 Intel DevCloud for oneAPI 和 Intel Optimization for PyTorch基于BERT预训练模型的命名体识别任务语料介绍数据集构建使用示例 命名体识别模型前向传播模型训练 结果 参考资料 比赛:https://marketing.csdn.net/p/f3…

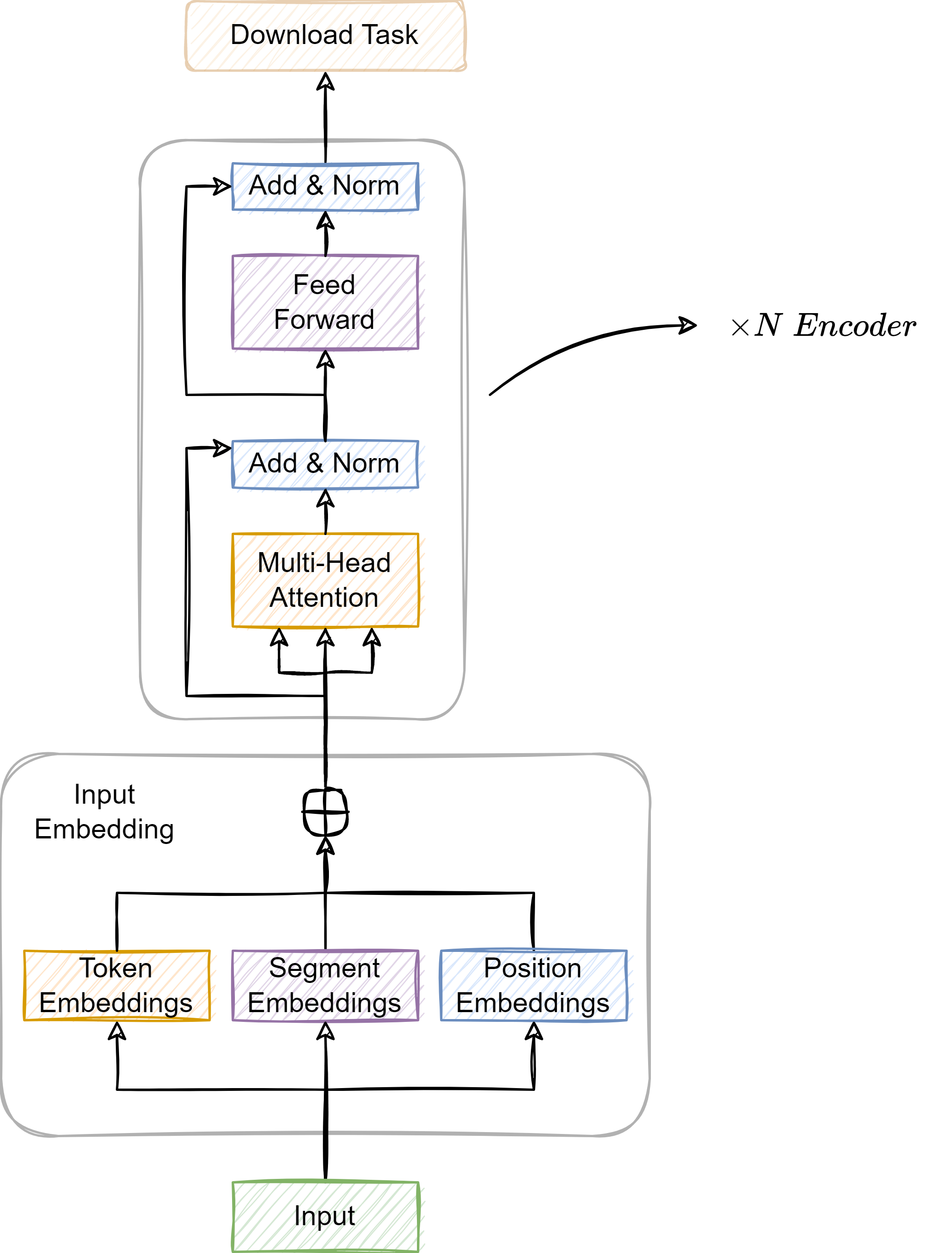
简洁高效的 NLP 入门指南: 200 行实现 Bert 文本分类 TensorFlow 代码纯享版
简洁高效的 NLP 入门指南: 200 行实现 Bert 文本分类 TensorFlow 代码纯享版 概述NLP 的不同任务Bert 概述MLM 任务 (Masked Language Modeling)TokenizeMLM 的工作原理为什么使用 MLM NSP 任务 (Next Sentence Prediction)NSP 任务的工作原理NSP 任务栗子NSP 任务的调整和局限…
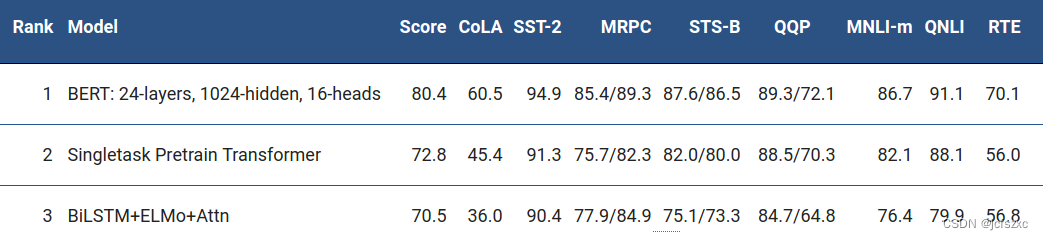
【深度学习:开源BERT】 用于自然语言处理的最先进的预训练
【深度学习:开源BERT】 用于自然语言处理的最先进的预训练 是什么让 BERT 与众不同?双向性的优势使用云 TPU 进行训练BERT 结果让 BERT 为您所用 自然语言处理 (NLP) 面临的最大挑战之一是训练数据的短缺。由于 NLP 是一个具有许多…
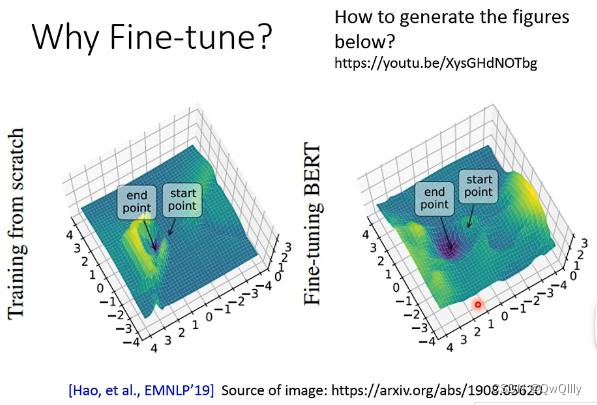
2022最新版-李宏毅机器学习深度学习课程-P50 BERT的预训练和微调
模型输入无标签文本(Text without annotation),通过消耗大量计算资源预训练(Pre-train)得到一个可以读懂文本的模型,在遇到有监督的任务是微调(Fine-tune)即可。
最具代表性是BERT&…
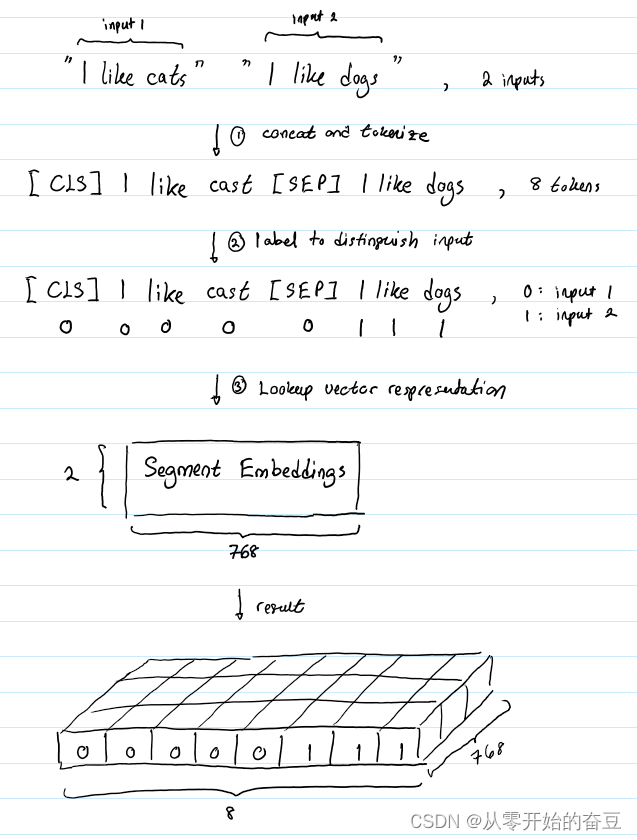
深度学习(七):bert理解之输入形式
传统的预训练方法存在一些问题,如单向语言模型的局限性和无法处理双向上下文的限制。为了解决这些问题,一种新的预训练方法随即被提出,即BERT(Bidirectional Encoder Representations from Transformers)。通过在大规模…

使用 BERT 进行文本分类 (01/3)
摄影:Max Chen on Unsplash 一、说明 这是使用 BERT 语言模型的一系列文本分类演示的第一部分。以文本的分类作为例,演示它们的调用过程。
二、什么是伯特? BERT 代表 来自变压器的双向编码器表示。 首先,转换器是一种深度学习模…

看了这篇你还不懂BERT,那你就过来打死我吧
目录
1. Word Embedding. 1
1.1 基于共现矩阵的词向量... 1
1.2 基于语言模型的词向量... 2
2. RNN/LSTM/GRU.. 5
2.1 RNN.. 5
2.2 LSTM 通过门的机制来避免梯度消失... 6
2.3 GRU 把遗忘门和输入门合并成一个更新门... 6
3. seq2seq模型... 8
3.1 朴素的seq2seq模型.…
大型语言模型:SBERT — Sentence-BERT
slavahead 一、介绍 Transformer 在 NLP 方面取得了进化进步,这已经不是什么秘密了。基于转换器,许多其他机器学习模型已经发展起来。其中之一是BERT,它主要由几个堆叠的变压器编码器组成。除了用于情感分析或问答等一系列不同的问题外&#…
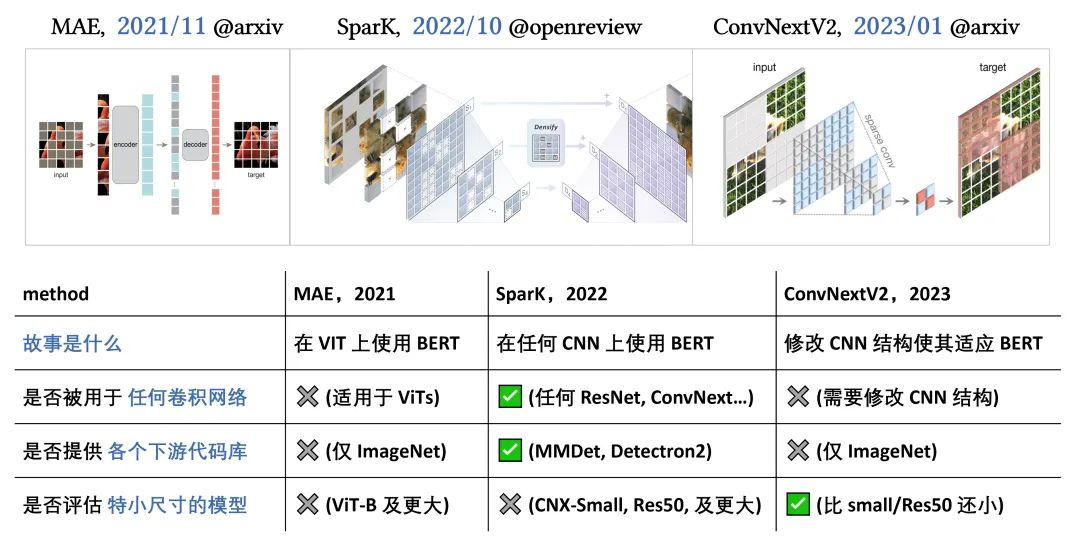
ICLR Spotlight | 卷积网络上的首个BERT/MAE预训练,ResNet也能用
“删除-再恢复” 形式的自监督预训练可追溯到 2016 年,早于 18 年的 BERT 与 21 年的 MAE。然而在长久的探索中,这种 BERT/MAE 式的预训练算法仍未在卷积模型上成功(即大幅超过有监督学习)。本篇 ICLR Spotlight 工作 “Designing…
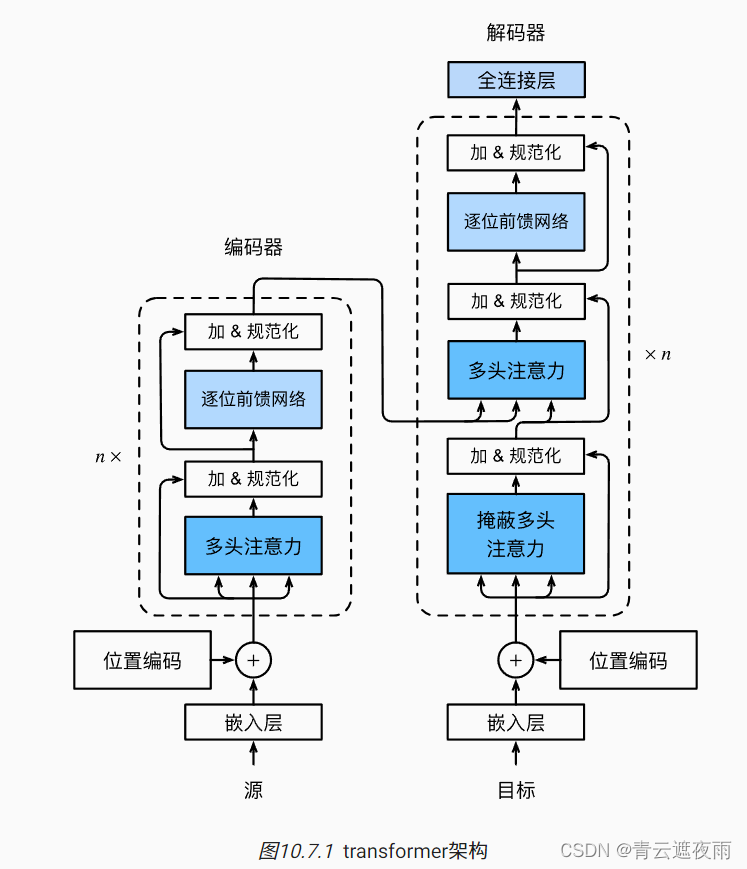
Bert基础(一)--transformer概览
1、简介
当下最先进的深度学习架构之一,Transformer被广泛应用于自然语言处理领域。它不单替代了以前流行的循环神经网络(recurrent neural network, RNN)和长短期记忆(long short-term memory, LSTM)网络,并且以它为基础衍生出了诸如BERT、GPT-3、T5等…

Bert模型from_pretrained报网络错误解决办法
问题描述: 服务器或者本地运行以下代码时报网络连接错误:
from transformers import AutoTokenizermodel_checkpoint "distilbert-base-uncased"
tokenizer AutoTokenizer.from_pretrained(model_checkpoint, use_fastTrue, cache_dir./cac…
AI大模型中的Bert
1.全方位上下文理解:与以前的模型(例如GPT)相比,BERT能够双向理解上下文,即同时考虑一个词 的左边和右边的上下文。这种全方位的上下文理解使得BERT能够更好地理解语言,特别是在理解词义、 消歧等复杂任务上…
bert ranking listwise demo
下面是用bert 训练listwise rank 的 demo
import torch
from torch.utils.data import DataLoader, Dataset
from transformers import BertModel, BertTokenizer
from sklearn.metrics import pairwise_distances_argmin_minclass ListwiseRankingDataset(Dataset):def __in…

深入理解BERT Transformer ,不仅仅是注意力机制
作者: 龙心尘 时间:2019年3月 出处:https://blog.csdn.net/longxinchen_ml/article/details/89058309
大数据文摘与百度NLP联合出品 作者:Damien Sileo 审校:百度NLP、龙心尘 编译:张驰、毅航
为什么BERT…

论文阅读 BERT GPT - transformer在NLP领域的延伸
文章目录 不会写的很详细,只是为了帮助我理解在CV领域transformer的拓展1 摘要1.1 BERT - 核心1.2 GPT - 核心 2 模型架构2.1 概览 3 区别3.1 finetune和prompt 3.2 transformer及训练总结 不会写的很详细,只是为了帮助我理解在CV领域transformer的拓展 …

BERT大模型:英语NLP的里程碑
BERT的诞生与重要性
BERT(Bidirectional Encoder Representations from Transformers)大模型标志着自然语言处理(NLP)领域的一个重要转折点。作为首个利用掩蔽语言模型(MLM)在英语语言上进行预训练的模型&…
基于BERTopic模型的中文文本主题聚类及可视化
文章目录 BERTopic简介模型加载地址文本加载数据处理BERTopic模型构建模型结果展示主题可视化总结BERTopic简介
BERTopic论文地址:BERTopic: Neural topic modeling with a class-based TF-IDF procedure
BERTopic是一种结合了预训练模型BERT和主题建模的强大工具。它允许我…
【第二课课后作业】书生·浦语大模型实战营-轻松玩转书生·浦语大模型趣味Demo
目录 轻松玩转书生浦语大模型趣味Demo课后作业1. 基础作业1.1 使用 InternLM-Chat-7B 模型生成 300 字的小故事:1.2 熟悉 hugging face 下载功能,使用 huggingface_hub python 包,下载 InternLM-20B 的 config.json 文件到本地 2. 进阶作业2.…
Kaggle - LLM Science Exam(一):赛事概述、数据收集、BERT Baseline
文章目录 一、赛事概述1.1 OpenBookQA Dataset1.2 比赛背景1.3 评估方法和代码要求1.4 比赛数据集1.5 优秀notebook 二、BERT Baseline2.1 数据预处理2.2 定义data_collator2.3 加载模型,配置trainer并训练2.4 预测结果并提交2.5 deberta-v3-large 1k Wikiÿ…
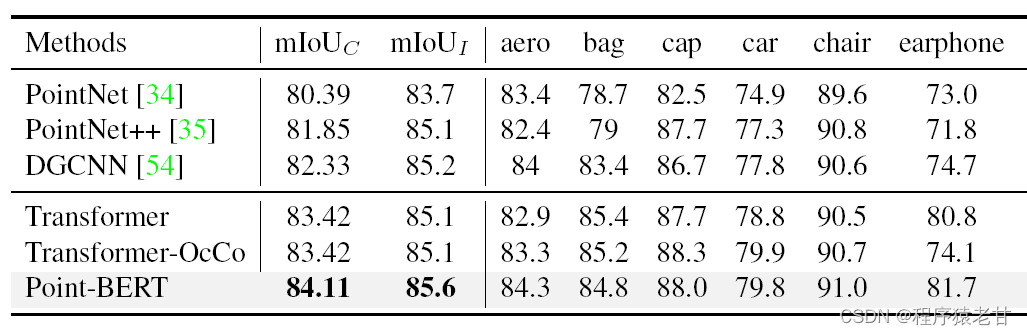
Point-BERT:一种基于Transformer架构的点云深度网络
目录 1. 前言 2. Point Tokenization 3. Transformer Backbone 4. Masked Point Modeling 5. Experiments Reference 1. 前言
从PointNet [1] 开始,点云深度网络逐渐成为解决点云特征提取与语义分析的主要研究方向。尤其在OpenAI的GPT模型获得了突破性成果后&#…
Bert-VITS-2 效果挺好的声音克隆工具
持中日英三语训练和推理。内置干声分离,切割和标注工具,开箱即用。请点下载量右边的符号查看镜像所对应的具体版本号。
教程地址:
sjjCodeWithGPU | 能复现才是好算法CodeWithGPU | GitHub AI算法复现社区,能复现…
基于BERT+BiLSTM+CRF模型与新预处理方法的古籍自动标点
摘要
古文相较于现代文不仅在用词、语法等方面存在巨大差异,还缺少标点,使人难以理解语义。采用人工方式对古文进行标点既需要有较高的文学水平,还需要对历史文化有一定了解。为提高古文自动标点的准确率,将深层语言模型BERT与双向长短记忆网络和条件随机场模型(BiLSTM+C…

使用padlle hub进行BERT Fine-Tune 中文-文本分类/蕴含 下游任务
使用padlle hub进行BERT Fine-Tune 中文-文本分类/蕴含 下游任务写在前面1.相关技术PaddleHub:预训练模型:Bert_chinese_L-12_H-768_A-12Bert下游任务2.使用步骤-以文本蕴含为例环境准备数据处理数据集解压数据集数据集展示处理数据集自定义Hub数据集PaddleHub分类数…
huggingface 自定义模型finetune训练测试--bert多任务
背景:
需要将bert改为多任务,但是官方仅支持多分类、二分类,并不支持多任务。改为多任务时我们需要修改输出层、loss、评测等。如果需要在bert结尾添加fc等也可以参考该添加方式。
代码
修改model
这里把BertForSequenceClassification改…
![[oneAPI] BERT](https://img-blog.csdnimg.cn/e086f4c3fcaf4edda6062074fd7764c6.png)
[oneAPI] BERT
[oneAPI] BERT BERT训练过程Masked Language Model(MLM)Next Sentence Prediction(NSP)微调 总结基于oneAPI代码 比赛:https://marketing.csdn.net/p/f3e44fbfe46c465f4d9d6c23e38e0517 Intel DevCloud for oneAPI&…
BERT 相关资源整理
文章
NLP文档挖宝(3)——能够快速设计参数的TrainingArguments类 使用 PyTorch 进行知识蒸馏 调节学习率 Huggingface简介及BERT代码浅析 使用huggingface的Transformers预训练自己的bert模型FineTuning BERT 预训练 预训练模型:从BERT到XLNet、RoBERTa、ALBERT
B…
BERT 面试题 2
1、请简要介绍BERT的网络结构,预训练任务,和优势。
BERT的网络结构是基于Transformer的Encoder部分,由多层自注意力机制和前馈神经网络组成。BERT的预训练任务有两个:Masked Language Model(MLM)和Next Se…

Bert和LSTM:情绪分类中的表现
一、说明 这篇文章的目的是评估和比较 2 种深度学习算法(BERT 和 LSTM)在情感分析中进行二元分类的性能。评估将侧重于两个关键指标:准确性(衡量整体分类性能)和训练时间(评估每种算法的效率)。…
【BERT】深入理解BERT模型1——模型整体架构介绍
前言
BERT出自论文:《BERT:Pre-training of Deep Bidirectional Transformers for Language Understanding》 2019年
近年来,在自然语言处理领域,BERT模型受到了极为广泛的关注,很多模型中都用到了BERT-base或者是BE…

NLP-D31-《动手学pytorch》完结BERTLayer_norm
---------0439我感觉今天终于可以阶段性地看完沐沐的课了!!!狂喜!马上终于可以看看宝可梦了嘿嘿嘿!
1、ELMo&GPT&BERT对比 2\位置嵌入参数
全局来看,应该也就只有一个位置嵌入参数
3\BERT的val…
人工智能自然语言处理:语言之美,算法之智
导言 自然语言处理(Natural Language Processing, NLP)是人工智能领域中备受关注的分支,致力于让计算机能够理解、处理和生成人类语言。本文将深入研究人工智能在自然语言处理领域的关键技术、应用场景以及未来发展趋势。
1. 简介 自然语言处…

本地训练,立等可取,30秒音频素材复刻霉霉讲中文音色基于Bert-VITS2V2.0.2
之前我们使用Bert-VITS2V2.0.2版本对现有的原神数据集进行了本地训练,但如果克隆对象脱离了原神角色,我们就需要自己构建数据集了,事实上,深度学习模型的性能和泛化能力都依托于所使用的数据集的质量和多样性,本次我们…
【nlp】4.3 nlp中常用的预训练模型(BERT及其变体)
nlp中常用的预训练模型 1 当下NLP中流行的预训练模型1.1 BERT及其变体1.2 GPT1.3 GPT-2及其变体1.4 Transformer-XL1.5 XLNet及其变体1.6 XLM1.7 RoBERTa及其变体1.8 DistilBERT及其变体1.9 ALBERT1.10 T5及其变体1.11 XLM-RoBERTa及其变体2 预训练模型说明3 预训练模型的分类1…

Re60:读论文 FILM Adaptable and Interpretable Neural Memory Over Symbolic Knowledge
诸神缄默不语-个人CSDN博文目录 诸神缄默不语的论文阅读笔记和分类
论文名称:Adaptable and Interpretable Neural Memory Over Symbolic Knowledge 模型名称:Fact Injected Language Model (FILM)
NAACL版网址:https://aclanthology.org/2…

On the Sentence Embeddings from Pre-trained Language Models paper阅读
abstract
没有经过fine-tuning的embedding在语义计算上效果非常差bert总是一个非平滑的各向异性的空间语义表达,对于以相似度的计算有害处本文想办法将其转化成平滑的并且各项同性的高斯分布的表达,并且是通过无监督学习来做到的,效果得到了…

白话 Transformer 原理-以 BERT 模型为例
白话 Transformer 原理-以 BERT 模型为例
第一部分:引入
1-向量
在数字化时代,数学运算最小单位通常是自然数字,但在 AI 时代,这个最小单元变成了向量,这是数字化时代计算和智能化时代最重要的差别之一。
举个例子:银行在放款前,需要评估一个人的信用度;对于用户而…
word2vec,BERT,GPT相关概念
词嵌入(Word Embeddings)
词嵌入通常是针对单个词元(如单词、字符或子词)的。然而,OpenAI 使用的是预训练的 Transformer 模型(如 GPT 和 BERT),这些模型不仅可以为单个词元生成嵌入…
深度解析BERT:从理论到Pytorch实战
本文从BERT的基本概念和架构开始,详细讲解了其预训练和微调机制,并通过Python和PyTorch代码示例展示了如何在实际应用中使用这一模型。我们探讨了BERT的核心特点,包括其强大的注意力机制和与其他Transformer架构的差异。 关注TechLead&#x…
![【NLP】什么是语义搜索以及如何实现 [Python、BERT、Elasticsearch]](https://img-blog.csdnimg.cn/img_convert/9512e7ff7193be9616e602a7bfd51f74.jpeg)
【NLP】什么是语义搜索以及如何实现 [Python、BERT、Elasticsearch]
语义搜索是一种先进的信息检索技术,旨在通过理解搜索查询和搜索内容的上下文和含义来提高搜索结果的准确性和相关性。与依赖于匹配特定单词或短语的传统基于关键字的搜索不同,语义搜索会考虑查询的意图、上下文和语义。
语义搜索在搜索结果的精度和相关…
【论文解读】(如何微调BERT?) How to Fine-Tune BERT for Text Classification?
文章目录 论文信息1. 论文内容2. 论文结论2.1 微调流程2.2 微调策略(Fine-Tuning Strategies)2.3 Further Pretrain 3. 论文实验介绍3.1 实验数据集介绍3.2 实验超参数3.3 Fine-Tuning策略探索3.3.1 处理长文本3.3.2 不同层的特征探索3.3.3 学习率探索(灾难性遗忘探…
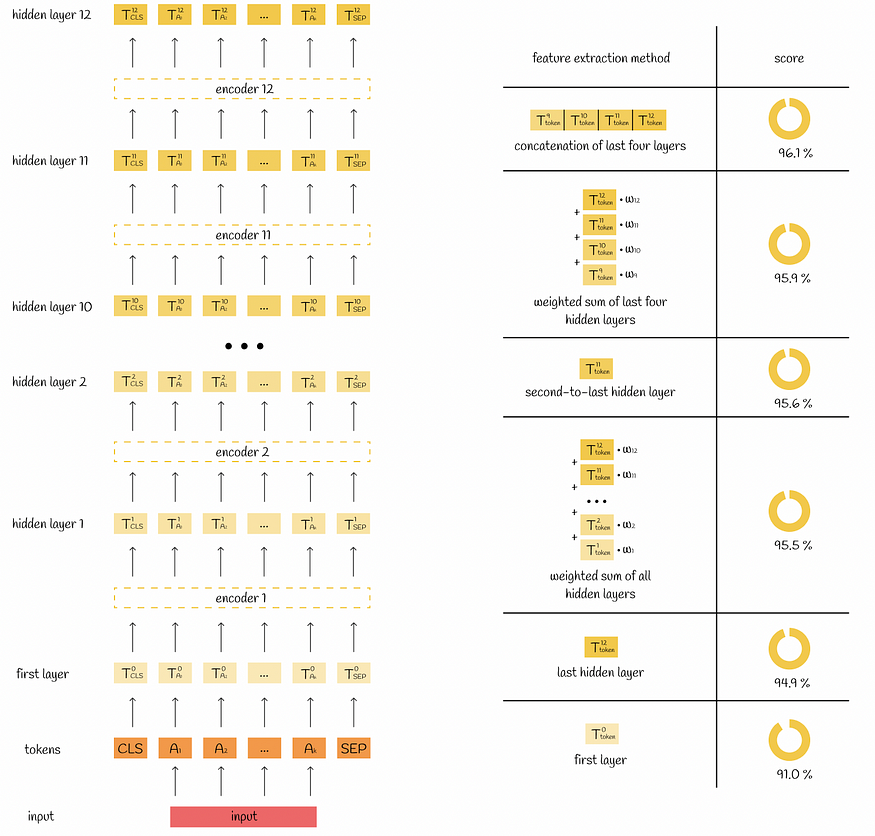
Python - Bert-VITS2 自定义训练语音
目录
一.引言
二.前期准备
1.Conda 环境搭建
2.Bert 模型下载
3.预训练模型下载
三.数据准备
1.音频文件批量处理
2.训练文件地址生成
3.模型训练配置生成
4.训练文件重采样
5.Tensor pt 文件生成
四.模型训练
1.预训练模型
2.模型训练
3.模型收菜
五.总结 一…
Bert-vits2最终版Bert-vits2-2.3云端训练和推理(Colab免费GPU算力平台)
对于深度学习初学者来说,JupyterNoteBook的脚本运行形式显然更加友好,依托Python语言的跨平台特性,JupyterNoteBook既可以在本地线下环境运行,也可以在线上服务器上运行。GoogleColab作为免费GPU算力平台的执牛耳者,更…
BERT Intro
继续NLP的学习,看完理论之后再看看实践,然后就可以上手去kaggle做那个入门的project了orz。
参考:
1810.04805.pdf (arxiv.org)
BERT 论文逐段精读【论文精读】_哔哩哔哩_bilibili
(强推!)2023李宏毅讲解大模型鼻祖BERT,一小时…
【中文编码】利用bert-base-chinese中的Tokenizer实现中文编码嵌入
最近接触文本处理,查询了一些资料,记录一下中文文本编码的处理方法吧。 先下载模型和词表:bert-base-chinese镜像下载 如下图示,下载好的以下文件均存放在 bert-base-chinese 文件夹下 1. 词编码嵌入简介 按我通俗的…
bert-vits2本地部署报错疑难问题汇总
环境:
bert-vits2.3 win 和wsl
问题描述:
bert-vits2本地部署报错疑难问题汇总
解决方案:
问题1:
Conda安装requirements里面依赖出现ERROR: No matching distribution found for opencc1.1.6
解决方法
需要在 Python 3.11 上使用 Op…
NLP——ELMO;BERT;Transformers
文章目录 ELMOELMO 简介ELMO 优点利用了多层的 hidden 表示ELMO 缺点 BERTBERT V.S. ELMO两种预训练任务Object1: Masked Language ModelObject2: Next sentence prediction 训练细节如何使用 BERTBERT 应用——垃圾邮件分类 Transformerself-attentionMulti-head AttentionTra…

BERT模型的若干问题整理记录 思考
1.BERT的基本原理是什么?
BERT来自Google的论文Pre-training of Deep Bidirectional Transformers for Language Understanding,BERT是”Bidirectional Encoder Representations from Transformers”的首字母缩写,整体是一个自编码语言模型&…
pytorch+huggingface+bert实现一个文本分类
pytorchhuggingfacebert实现一个文本分类
1,下载模型
bert模型的目前方便的有两种:一种是huggingface_hub以及/AutoModel.load, 一种torch.hub。
(1) 使用huggingface_hub或者下载模型。
# repo_id:模型名称or用户名/模型名称from huggingface_hub i…

详细介绍Sentence-BERT:使用连体BERT网络的句子嵌入
Sentence-BERT:Sentence Embeddings using Siamese BERT-Networks 使用连体BERT网络的句子嵌入 BERT和RoBERTa在诸如语义文本相似性(STS)的句子对回归任务上创造了新的最优的性能。然而,它要求将两个句子都输入网络,这导致了巨大的…
bert中 [CLS] 和 [SEP]怎么使用
BERT(Bidirectional Encoder Representations from Transformers)是一种基于Transformer的预训练语言模型。在BERT中,[CLS] 和 [SEP] 是特殊的标记(tokens),用于表示句子的开始和结束,或者在处理…
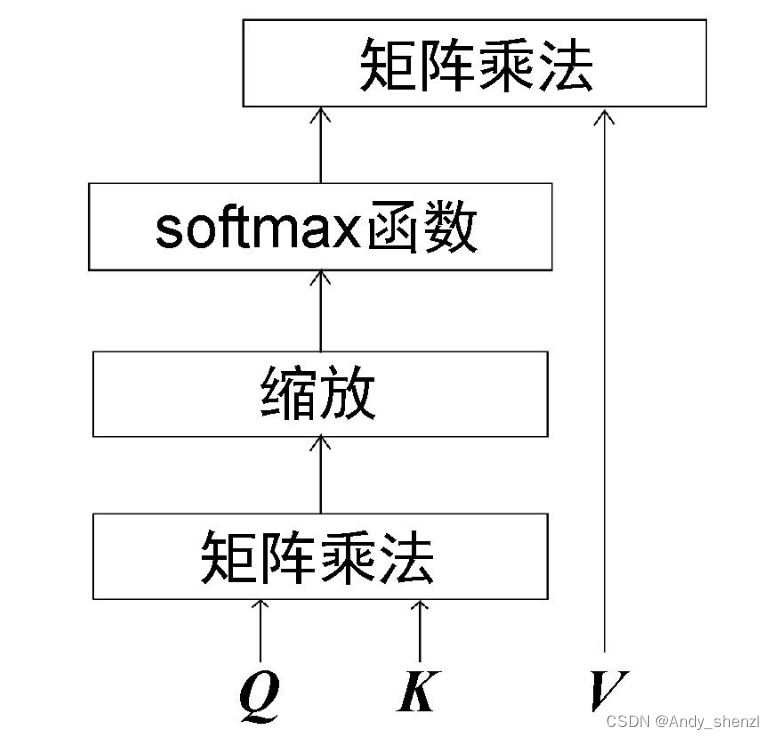
LangChain+LLM实战---BERT主要的创新之处和注意力机制中的QKV
BERT主要的创新之处
BERT(Bidirectional Encoder Representations from Transformers)是一种基于Transformer架构的预训练语言模型,由Google在2018年提出。它的创新之处主要包括以下几个方面:
双向性(Bidirectional&…
让chatGPT使用Tensor flow Keras组装Bert,GPT,Transformer
让chatGPT使用Tensor flow Keras组装Bert,GPT,Transformer implement Transformer Model by Tensor flow Kerasimplement Bert model by Tensor flow Kerasimplement GPT model by Tensor flow Keras 本文主要展示Transfomer, Bert, GPT的神经网络结构之间的关系和差异。网络上…

首次引入大模型!Bert-vits2-Extra中文特化版40秒素材复刻巫师3叶奈法
Bert-vits2项目又更新了,更新了一个新的分支:中文特化,所谓中文特化,即针对中文音色的特殊优化版本,纯中文底模效果百尺竿头更进一步,同时首次引入了大模型,使用国产IDEA-CCNL/Erlangshen-Megat…
大型语言模型,第 1 部分:BERT
一、介绍 2017是机器学习中具有历史意义的一年,当变形金刚模型首次出现在现场时。它在许多基准测试上都表现出色,并且适用于数据科学中的许多问题。由于其高效的架构,后来开发了许多其他基于变压器的模型,这些模型更专注于特定任务…
简洁高效的 NLP 入门指南: 200 行实现 Bert 文本分类 (Pytorch 版)
简洁高效的 NLP 入门指南: 100 行实现 Bert 文本分类 Pytorch 版 概述NLP 的不同任务Bert 概述MLM 任务 (Masked Language Modeling)TokenizeMLM 的工作原理为什么使用 MLM NSP 任务 (Next Sentence Prediction)NSP 任务的工作原理NSP 任务栗子NSP 任务的调整和局限性 安装和环…
使用tensorflow2.15.0版跑bert模型遇到的问题记录
背景
使用官方的bert模型https://github.com/google-research/bert作文本分类时(运行run_classifier.py函数),遇到的一些问题记录
问题记录
官方模型要求的版本是tensorflow > 1.11.0,现在安装的是2.15.0,2.x版和1.x版之间有一些函数变…
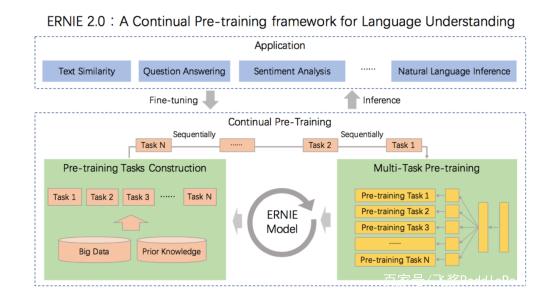
word2Vec进阶 -Bert
Word2Vec进阶 - Bert – 潘登同学的NLP笔记 文章目录Word2Vec进阶 - Bert -- 潘登同学的NLP笔记Bert介绍BERT的结构Bert的输入Bert的输出预训练任务Masked Language Model(MLM)Next Sentence Prediction(NSP)总结ERNIEERNIE2.0预训…

简要介绍 | 深度学习中的自注意力机制:原理与挑战
注1:本文系“简要介绍”系列之一,仅从概念上对深度学习中的自注意力机制进行非常简要的介绍,不适合用于深入和详细的了解。 注2:"简要介绍"系列的所有创作均使用了AIGC工具辅助 深度学习中的自注意力机制:原…

【NLP实战】基于Bert和双向LSTM的情感分类【下篇】
文章目录前言简介第一部分关于pytorch lightning保存模型的机制关于如何读取保存好的模型完善测试代码第二部分第一次训练出的模型的过拟合问题如何解决过拟合后记前言
本文涉及的代码全由博主自己完成,可以随意拿去做参考。如对代码有不懂的地方请联系博主。
博主…
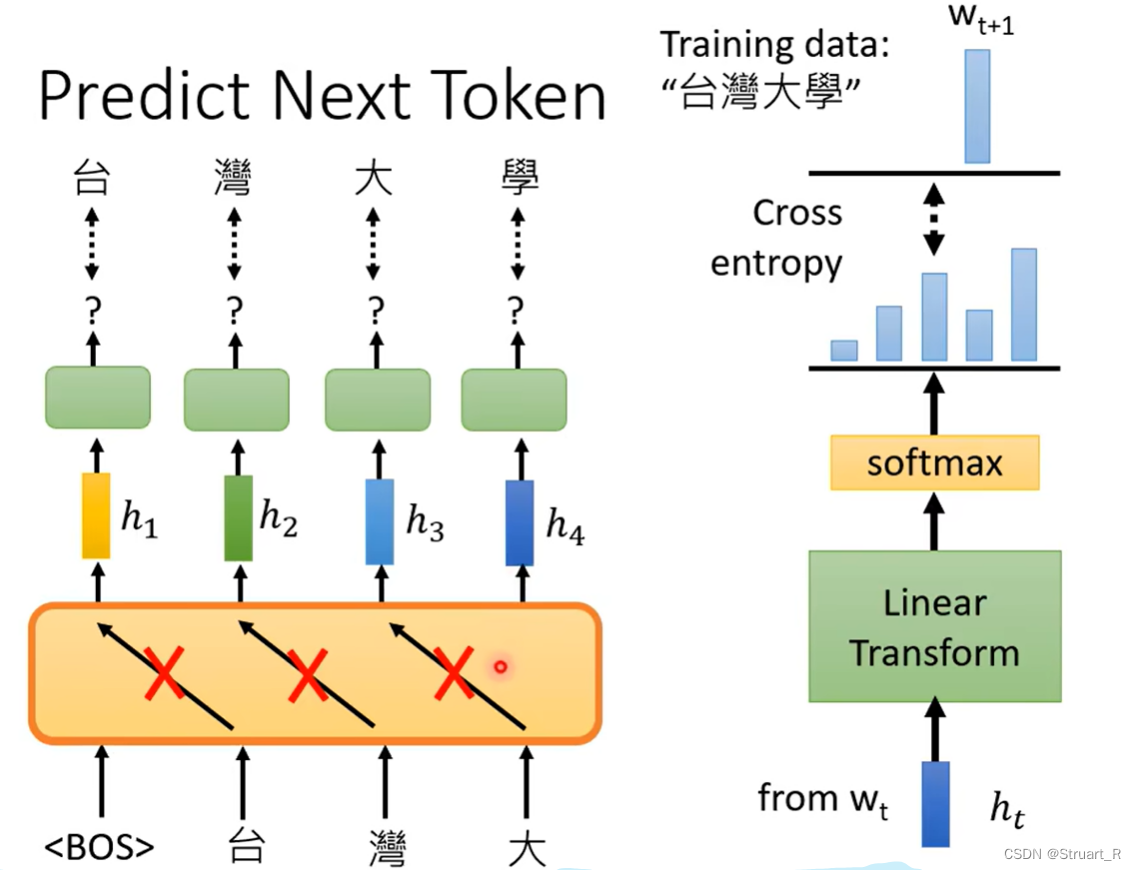
NLP(4)--BERT
目录
一、自监督学习
二、BERT的两个问题
三、GLUE
四、BERT与Transformer的关系
五、BERT的训练方式
六、BERT的四个例子
1、语句分类(情感分析)
2、词性标注
3、立场分析
4、问答系统
七、BERT的后续
1、为什么预训练后的微调可以满足多…
实现bert训练 人工智能模型
实现BERT的训练相对复杂,但以下是一个简单的示例代码,用于使用Hugging Face库中的transformers模块在PyTorch中训练BERT模型:
import torch
from torch.utils.data import DataLoader
from transformers import BertTokenizer, BertForSeque…
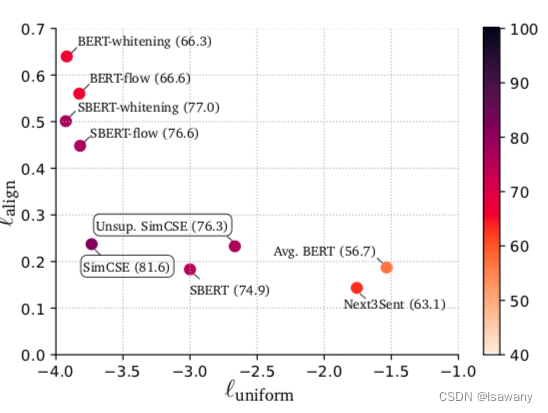
论文笔记--SimCSE: Simple Contrastive Learning of Sentence Embeddings
论文笔记--SimCSE: Simple Contrastive Learning of Sentence Embeddings 1. 文章简介2. 文章概括3 文章重点技术3.1 对比学习 Contrastive Learning3.2 Unsupervised SimCSE3.3 Supervised SimCSE3.4 Anisotropy3.5 Alignment and Uniformity 4. 文章亮点5. 原文传送门6. Refe…
P73 bert奇闻
同一个字,前后接的不同,词汇的意思不同,通过bert 之后输出的向量也不一样。 bert 输出后的向量包含上下文的信息。 比如 吃苹果 和苹果电脑中的 果,向量不一样。 DNA 分类 把DNA 的 A T C G 用 we you he she 表示,然…
【动手学深度学习-Pytorch版】BERT预测系列——BERTModel
本小节主要实现了以下几部分内容:
从一个句子中提取BERT输入序列以及相对的segments段落索引(因为BERT支持输入两个句子)BERT使用的是Transformer的Encoder部分,所以需要需要使用Encoder进行前向传播:输出的特征等于词…
自然语言处理实战项目8- BERT模型的搭建,训练BERT实现实体抽取识别的任务
大家好,我是微学AI,今天给大家介绍一下自然语言处理实战项目8- BERT模型的搭建,训练BERT实现实体抽取识别的任务。BERT模型是一种用于自然语言处理的深度学习模型,它可以通过训练来理解单词之间的上下文关系,从而为下游…

Lecture 11 Contextual Representation
目录 Problems with Word Vectors/Embeddings 词向量/嵌入的问题RNN 语言模型Bidirectional RNN 双向 RNNEmbeddings from Language Models 基于语言模型的嵌入ELMo 架构Downstream Task: POS Tagging 下游任务:词性标注ELMo 的表现如何?Other Findings上…
机器学习深度学习——BERT(来自transformer的双向编码器表示)
👨🎓作者简介:一位即将上大四,正专攻机器学习的保研er 🌌上期文章:机器学习&&深度学习——transformer(机器翻译的再实现) 📚订阅专栏:机器学习&am…
基于飞浆NLP的BERT-finetuning新闻文本分类
目录 1.数据预处理 2.加载模型 3.批训练 4.准确率 1.数据预处理 导入所需库 import numpy as np
from paddle.io import DataLoader,TensorDataset
from paddlenlp.transformers import BertForSequenceClassification, BertTokenizer
from sklearn.model_selection import tra…
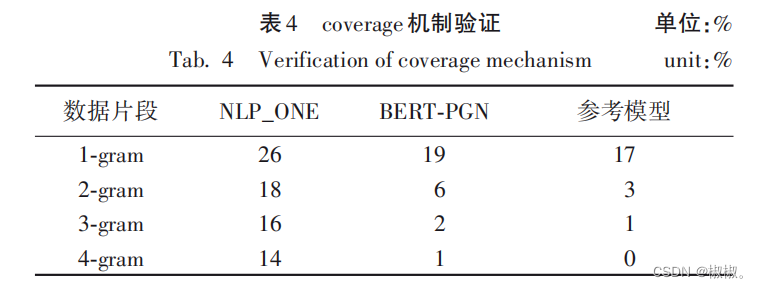
基于BERT-PGN模型的中文新闻文本自动摘要生成——文本摘要生成(论文研读)
基于BERT-PGN模型的中文新闻文本自动摘要生成(2020.07.08) 基于BERT-PGN模型的中文新闻文本自动摘要生成(2020.07.08)摘要:0 引言相关研究2 BERT-PGN模型2. 1 基于预训练模型及多维语义特征的词向量获取阶段2. 1. 1 BE…
微调bert做学术论文分类(以科大讯飞学术论文分类挑战赛为例)
代码
12-How to Fine-Tune BERT for Text Classification:链接:https://pan.baidu.com/s/1EKggbyC4ZW-ufnDW45eKzA 提取码:k3b2
baseline
链接:https://pan.baidu.com/s/12hkZNJjQ__FGAHiF3fifvQ 提取码:88tb
数据…
BERT: 面向语言理解的深度双向Transformer预训练
参考视频: BERT 论文逐段精读【论文精读】_哔哩哔哩_bilibili 背景
BERT算是NLP里程碑式工作!让语言模型预训练出圈!
使用预训练模型做特征表示的时候一般有两类策略:
1. 基于特征 feature based (Elmo)…
『NLP学习笔记』图解 BERT、ELMo和GPT(NLP如何破解迁移学习)
图解 BERT、ELMo和GPT(NLP如何破解迁移学习) 文章目录 一. 前言二. 示例-句子分类三. 模型架构3.1. 模型输入3.2. 模型输出四. BERT VS卷积神经网络五. 词嵌入新时代5.1. 简要回顾词嵌入Word Embedding5.2. ELMo: 上下文语境很重要5.3. ELMo的秘密是什么?5.4. ULM-FiT:将迁移…
Bert Encoder和Transformer Encoder有什么不同
前言:本篇文章主要从代码实现角度研究 Bert Encoder和Transformer Encoder 有什么不同?应该可以帮助你: 深入了解Bert Encoder 的结构实现深入了解Transformer Encoder的结构实现 本篇文章不涉及对注意力机制实现的代码研究。 注:…
LLM 系列——BERT——论文解读
一、概述
1、是什么 是单模态“小”语言模型,是一个“Bidirectional Encoder Representations fromTransformers”的缩写,是一个语言预训练模型,通过随机掩盖一些词,然后预测这些被遮盖的词来训练双向语言模型(编码器结构)。可以用于句子分类、词性分类等下游任务,本身…
nlp系列(7)实体识别(Bert)pytorch
模型介绍
本项目是使用Bert模型来进行文本的实体识别。
Bert模型介绍可以查看这篇文章:nlp系列(2)文本分类(Bert)pytorch_bert文本分类_牧子川的博客-CSDN博客
模型结构
Bert模型的模型结构: 数据介绍 …

阅读理解机器问答系统
机器问答系统流程如下图所示: 具体过程:
(1)准备知识库,可以从维基百科或者百度百科中获取,知识库主要是存储实体与实体介绍文本,也就是百科中的词条与词条介绍。
(2)流…
![心法利器[107] onnx和tensorRT的bert加速方案记录](https://img-blog.csdnimg.cn/img_convert/10e4893054f80e1aa02cb2febb3b0469.png)
心法利器[107] onnx和tensorRT的bert加速方案记录
心法利器 本栏目主要和大家一起讨论近期自己学习的心得和体会,与大家一起成长。具体介绍:仓颉专项:飞机大炮我都会,利器心法我还有。 2023年新一版的文章合集已经发布,获取方式看这里:又添十万字-CS的陋室2…
Transformer通俗笔记:从Word2Vec、Seq2Seq逐步理解到GPT、BERT
前言 我在写上一篇博客《22下半年》时,有读者在文章下面评论道:“july大神,请问BERT的通俗理解还做吗?”,我当时给他发了张俊林老师的BERT文章,所以没太在意。
直到今天早上,刷到CSDN上一篇讲B…
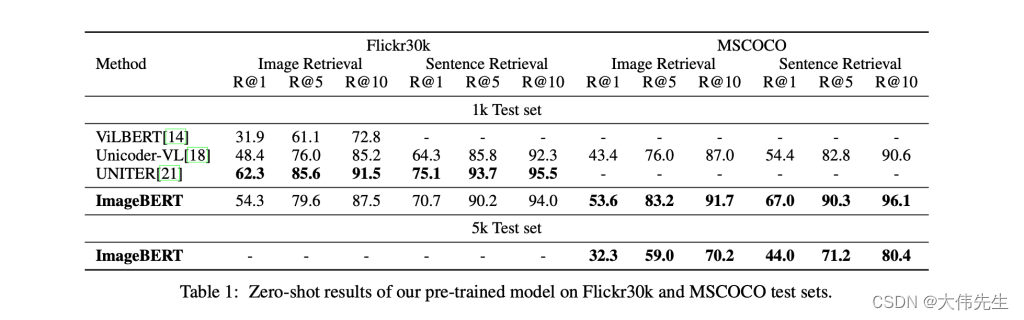
Microsoft 图像BERT,基于大规模图文数据的跨模态预训练
视觉语言任务是当今自然语言处理(NLP)和计算机视觉领域的热门话题。大多数现有方法都基于预训练模型,这些模型使用后期融合方法融合下游任务的多模态输入。然而,这种方法通常需要在训练期间进行特定的数据注释,并且对于…
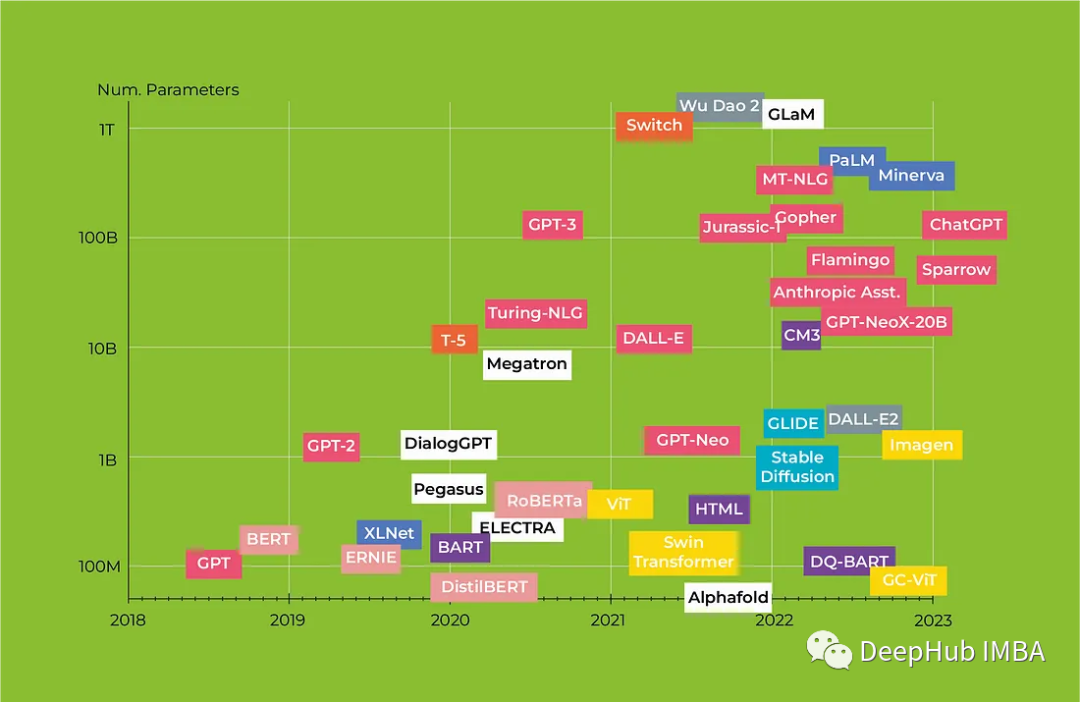
Transformers 2023年度回顾 :从BERT到GPT4
人工智能已成为近年来最受关注的话题之一,由于神经网络的发展,曾经被认为纯粹是科幻小说中的服务现在正在成为现实。从对话代理到媒体内容生成,人工智能正在改变我们与技术互动的方式。特别是机器学习 (ML) 模型在自然语言处理 (NLP) 领域取得…
预训练Bert添加new token的问题
问题
最近遇到使用transformers的AutoTokenizer的时候,修改vocab.txt中的[unused1]依然无法识别相应的new token。
实例: 我将[unused1]修改为了[TRI],句子中的[TRI]并没有被整体识别,而是识别为了[,T,RI,]。这明显是有问题的。…

NLP之Bert介绍和简单示例
文章目录 1. Bert 介绍2. 代码示例2.1 代码流程 1. Bert 介绍 2. 代码示例
from transformers import AutoTokenizertokenizer AutoTokenizer.from_pretrained("bert-base-chinese")
input_ids tokenizer.encode(欢迎来到Bert世界, return_tensorstf)
print(input…
BERT相关模型不能下载问题
Author:龙箬 Computer Application Technology Change the World with Data and Artificial Intelligence ! CSDNweixin_43975035 生有热烈,藏与俗常 由于网络原因,不能下载BERT相关模型 及 tokenizer urllib3.exceptions.MaxRetryError: HTTPSConnectio…
Huggingface简介及BERT代码浅析
Hugging face 是一家总部位于纽约的聊天机器人初创服务商,令它广为人知的是Hugging Face专注于NLP技术,拥有大型的开源社区,尤其是在github上开源的自然语言处理,预训练模型库 Transformers。最初叫 pytorch-pretrained-bert 。 安…
用Bert进行文本分类
BERT(Bidirectional Encoder Representations from Transformers)模型是一种基于Transformer架构的深度学习模型,主要用于自然语言处理任务。以下是对BERT模型的系统解释: 双向编码器(Bidirectional Encoder࿰…
NLP之Bert实现文本分类
文章目录 1. 代码展示2. 整体流程介绍3. 代码解读4. 报错解决4.1 解决思路4.2 解决方法 1. 代码展示
from tqdm import tqdm # 可以在循环中添加进度条x [1, 2, 3] # list
print(x[:10] [0] * -7)from transformers import AutoTokenizertokenizer AutoTokenizer.from_pr…
jupyter快速实现单标签及多标签多分类的文本分类BERT模型
jupyter实现pytorch版BERT(单标签分类版)
nlp-notebooks/Text classification with BERT in PyTorch.ipynb
通过改写上述代码,实现多标签分类
参考解决方案 ,我选择的解决方案是继承BertForSequenceClassification并改写&#…
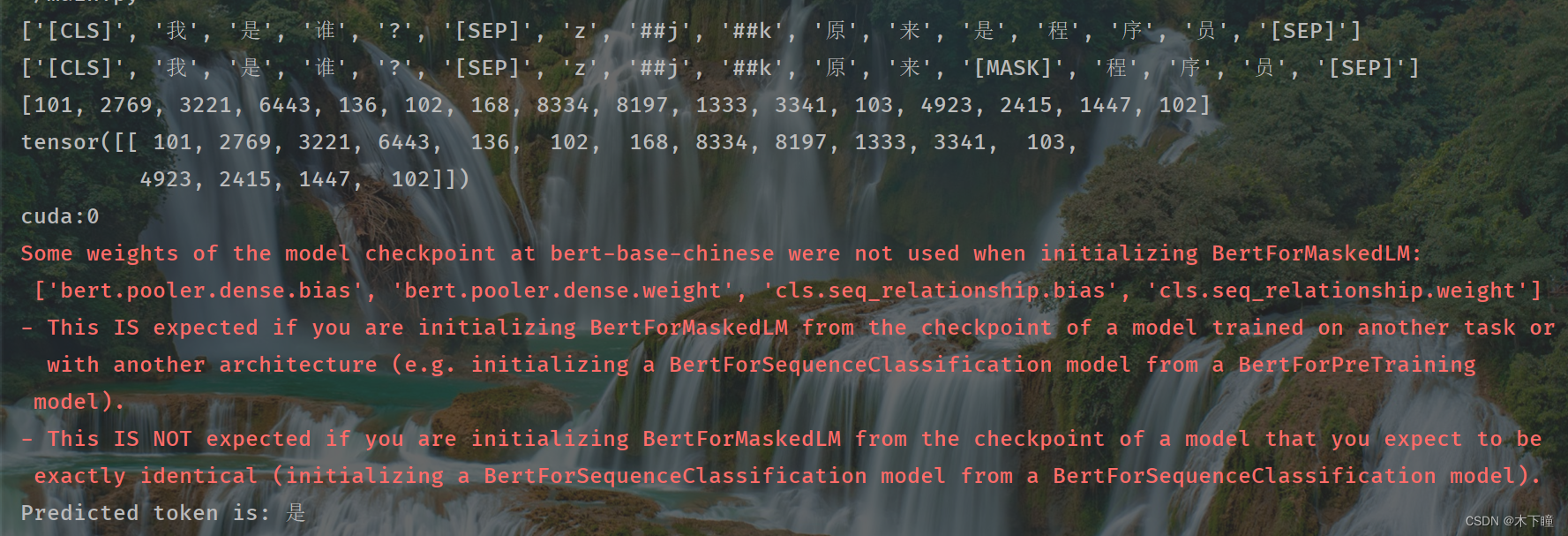
bert实现完形填空简单案例
使用 bert 来实现一个完形填空的案例,使用预训练模型 bert-base-chinese ,这个模型下载到跟代码同目录下即可,下载可参考:bert预训练模型下载-CSDN博客 通过这个案例来了解一下怎么使用预训练模型来完成下游任务,算是对…
VITS语音生成模型详解及中文语音生成训练
1 VITS模型介绍 VITS(Variational Inference with adversarial learning for end-to-end Text-to-Speech)是一种结合变分推理(variational inference)、标准化流(normalizing flows)和对抗训练的高表现力语…
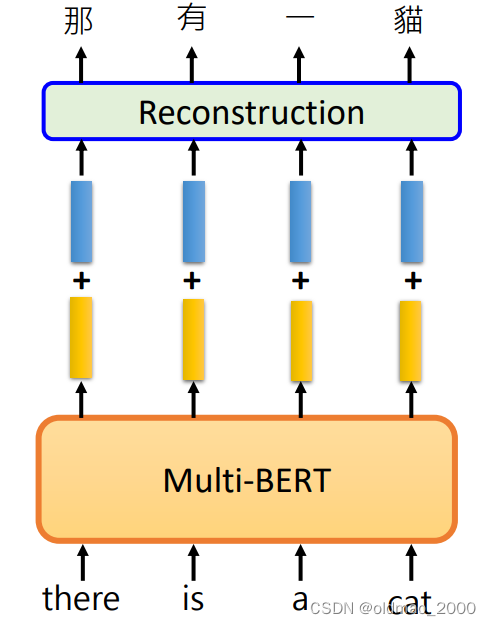
Self-Supervised Learning(2021补)
文章目录 引子X mask inputNext Sentence PredictionDownstream TasksGLUEBERT的四个用法情感分析POS标注自然语言推断Natural Language Inferencee (NLI)问答(抽取式) BERT的衍生模型Multi-lingual BERTGPT的野望(略) 发现有这一…
自然语言模型发展历程 及 Transformer GPT Bert简介
目录自然语言模型发展历程2003 年 Bengio 提出神经网络语言模型 NNLM,统一了 NLP 的特征形式——Embedding;2013 年 Mikolov 提出词向量 Word2vec,延续 NNLM 又引入了大规模预训练(Pretrain)的思路;2017 年…

解决方案TypeError: string indices must be integers
文章目录 一、现象:二、解决方案 一、现象:
PyTorch深度学习框架,运行bert-mini,本地环境是torch1.4-gpu,发现报错显示:TypeError: string indices must be integers
后面报字符问题,百度过找…
BERT:基于TensorFlow的BERT模型搭建中文问答系统模型
目录 1、导入所需库2、准备数据集3、对问题和答案进行分词4、构建模型5、编译模型6、训练模型7、评估模型8、使用模型进行预测 1、导入所需库
#导入numpy库,用于进行数值计算
import numpy as np#从Keras库中导入Tokenizer类,用于将文本转换为序列
from…
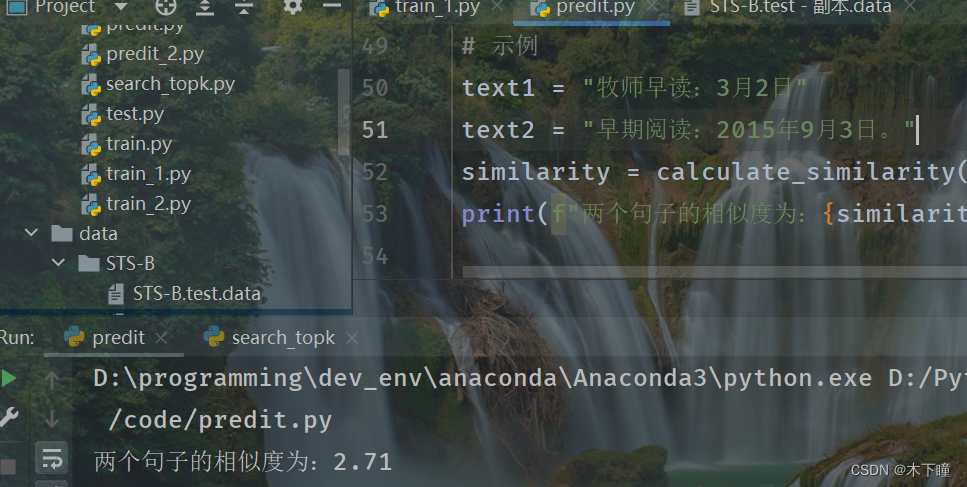
bert 相似度任务训练完整版
任务
之前写了一个相似度任务的版本:bert 相似度任务训练简单版本,faiss 寻找相似 topk-CSDN博客
相似度用的是 0,1,相当于分类任务,现在我们相似度有评分,不再是 0,1 了,分数为 0-5,数字越大…
2、BERT:自然语言处理的变革者
请参考之前写的:2、什么是BERT?-CSDN博客文章浏览阅读826次,点赞19次,收藏22次。BERT(Bidirectional Encoder Representations from Transformers)是Google在2018年提出的一种自然语言处理(NLP&…
LangChain+LLM实战---BERT和注意力机制中的QKV
BERT主要的创新之处
BERT(Bidirectional Encoder Representations from Transformers)是一种基于Transformer架构的预训练语言模型,由Google在2018年提出。它的创新之处主要包括以下几个方面:
双向性(Bidirectional&…
【Bert、T5、GPT】fine tune transformers 文本分类/情感分析
【Bert、T5、GPT】fine tune transformers 文本分类/情感分析 0、前言text classificationemotions 数据集data visualization analysisdataset to dataframelabel analysistext length analysis text > tokenstokenize the whole dataset fine-tune transformersdistilbert…
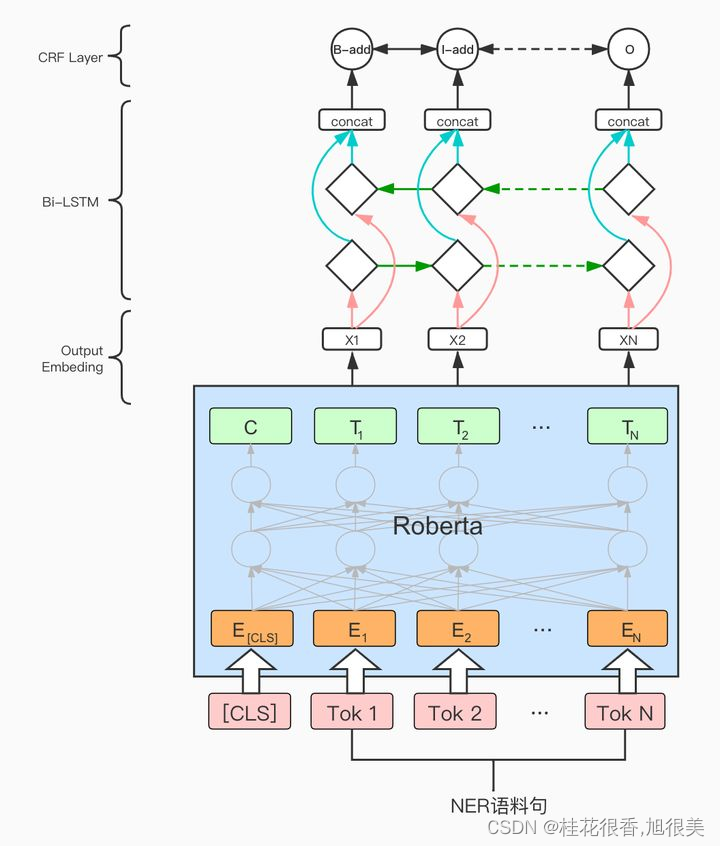
bert 和crf设置不同学习率(pytorch)
做ner 经典模式 bert crf,但是bert 和crf 的学习率不同:你的CRF层的学习率可能不够大 # 初始化模型参数优化器# config.learning_rate 3e-5no_decay [bias, LayerNorm.weight]optimizer_grouped_parameters [{params: [p for n, p in model.named_pa…
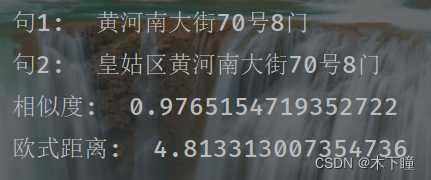
bert提取词向量比较两文本相似度
使用 bert-base-chinese 预训练模型做词嵌入(文本转向量)
模型下载:bert预训练模型下载-CSDN博客
参考文章:使用bert提取词向量 下面这段代码是一个传入句子转为词向量的函数
from transformers import BertTokenizer, BertMod…
关于MediaEval数据集的Dataset构建(Text部分-使用PLM BERT)
import random
import numpy as np
import pandas as pd
import torch
from transformers import BertModel,BertTokenizer
from tqdm.auto import tqdm
from torch.utils.data import Dataset
import re
"""参考Game-On论文"""
""&qu…
论文解读:Bert原理深入浅出
摘取于https://www.jianshu.com/p/810ca25c4502
任务1:Masked Language Model Maked LM 是为了解决单向信息问题,现有的语言模型的问题在于,没有同时利用双向信息,如 ELMO 号称是双向LM,但实际上是两个单向 RNN 构成的…

【好书推荐2】AI提示工程实战:从零开始利用提示工程学习应用大语言模型
【好书推荐2】AI提示工程实战:从零开始利用提示工程学习应用大语言模型 写在最前面AI辅助研发方向一:AI辅助研发的技术进展方向二:行业应用案例方向三:面临的挑战与机遇方向四:未来趋势预测方向五:与法规的…
【相关问题解答1】bert中文文本摘要代码:import时无法找到包时,几个潜在的原因和解决方法
【相关问题解答1】bert中文文本摘要代码 写在最前面问题1问题描述一些建议import时无法找到包时,几个潜在的原因和解决方法1. 模块或包的命名冲突解决方法: 2. 错误的导入路径解决方法: 3. 第三方库的使用错误解决方法: 4. 包未正…

阿里云-零基础入门NLP【基于深度学习的文本分类3-BERT】
文章目录 学习过程赛题理解学习目标赛题数据数据标签评测指标解题思路BERT代码 学习过程
20年当时自身功底是比较零基础(会写些基础的Python[三个科学计算包]数据分析),一开始看这块其实挺懵的,不会就去问百度或其他人,当时遇见困难挺害怕的…

ModuleNotFoundError: No module named ‘transformers.modeling_bert‘解决方案
大家好,我是爱编程的喵喵。双985硕士毕业,现担任全栈工程师一职,热衷于将数据思维应用到工作与生活中。从事机器学习以及相关的前后端开发工作。曾在阿里云、科大讯飞、CCF等比赛获得多次Top名次。现为CSDN博客专家、人工智能领域优质创作者。喜欢通过博客创作的方式对所学的…
wordvect嵌入和bert嵌入的区别
Word2Vec 嵌入和 BERT 嵌入之间有几个关键区别: 训练方式: Word2Vec:Word2Vec 是一个基于神经网络的词嵌入模型,它通过训练一个浅层的神经网络来学习单词的分布式表示。它有两种训练方式:连续词袋模型(CBOW…
HuggingFace踩坑记录-连不上,根本连不上
学习 transformers 的第一步,往往是几句简单的代码
from transformers import pipelineclassifier pipeline("sentiment-analysis")
classifier("We are very happy to show you the 🤗 Transformers library.")
""&quo…
《BERT》论文笔记
原文链接:
[1810.04805] BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding (arxiv.org)
原文笔记:
What:
BETR:Pre-training of Deep Bidirectional Transformers for Language Understand…
自然语言处理应用(三):微调BERT
微调BERT
微调(Fine-tuning)BERT是指在预训练的BERT模型基础上,使用特定领域或任务相关的数据对其进行进一步训练以适应具体任务的需求。BERT(Bidirectional Encoder Representations from Transformers)是一种基于Tr…

基于GPT3.5逆向 和 本地Bert-Vits2-2.3 的语音智能助手
文章目录 一、效果演示二、操作步骤三、架构解析 一、效果演示
各位读者你们好,我最近在研究一个语音助手的项目,是基于GPT3.5网页版的逆向和本地BertVits2-2.3 文字转语音,能实现的事情感觉还挺多,目前实现【无需翻墙࿰…

【NLP实战】基于Bert和双向LSTM的情感分类【中篇】
文章目录前言简介模型、优化器与损失函数选择神经网络的整体结构优化器选择损失函数选择需要导入的包和说明第一部分:搭建整体结构step1: 定义DataSet,加载数据step2:装载dataloader,定义批处理函数step3:生成层--预训练模块,测试…
使用NNI对BERT模型进行粗剪枝、蒸馏与微调
前言
模型剪枝(Model Pruning)是一种用于减少神经网络模型尺寸和计算复杂度的技术。通过剪枝,可以去除模型中冗余的参数和连接,从而减小模型的存储需求和推理时间,同时保持模型的性能。模型剪枝的一般步骤:…

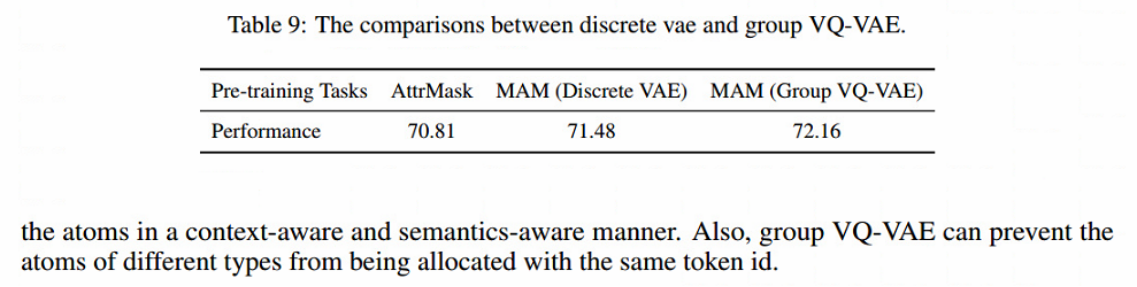
Knowledge-based-BERT(三)
多种预训练任务解决NLP处理SMILES的多种弊端,代码:Knowledge-based-BERT,原文:Knowledge-based BERT: a method to extract molecular features like computational chemists,代码解析继续downstream_task。模型框架如…

NLP学习笔记(七) BERT简明介绍
大家好,我是半虹,这篇文章来讲 BERT\text{BERT}BERT (Bidirectional Encoder Representations from Transformers)
原始论文请戳这里 0 概述
从某种程度上来说,深度学习至关重要的一环就是表征学习,也就是学习如何得到数据的向…

【自然语言处理】- 作业4: 预训练语言模型BERT实现与应用
课程链接: 清华大学驭风计划
代码仓库:Victor94-king/MachineLearning: MachineLearning basic introduction (github.com) 驭风计划是由清华大学老师教授的,其分为四门课,包括: 机器学习(张敏教授) , 深度学习(胡晓林教授), 计算…
BERT在GLUE数据集构建任务
0 Introduction
谷歌开源的BERT项目在Github上,视频讲解可以参考B站上的一个视频
1 GLUE部分基准数据集介绍
GLUE数据集官网GLUE数据集下载,建议下载运行这个download_glue_data.py文件进行数据集的下载,如果链接无法打开,运行…
自然语言处理实战10-文本处理过程与输入bert模型后的变化
大家好,我是微学AI,今天给大家介绍一下自然语言处理实战10-文本处理过程与输入bert模型后的变化,通过一段文本看看他的整个变化过程,经过怎样得变化才能输入到模型,输入到模型后文本又经过怎样的计算得到最后的结果。看…
Bert CNN信息抽取
Github参考代码:https://github.com/Wangpeiyi9979/IE-Bert-CNN
数据集来源于百度2019语言与智能技术竞赛,在上述链接中提供下载方式。
感谢作者提供的代码。
1、信息抽取任务
给定schema约束集合及句子sent,其中schema定义了关系P以及其…


文献阅读:Sentence-BERT:Sentence Embeddings using Siamese BERT-Networks
文献阅读:Sentence-BERT:Sentence Embeddings using Siamese BERT-Networks 1. 文章简介2. 主要方法介绍3. 主要实验内容 1. Unsupervised STS2. Supervised STS3. Downsteam SentEval Evaluation4. Ablation Study 4. 结论 & 思考 文献链接&#x…
【零基础-4】PaddlePaddle学习Bert
概要
【零基础-1】PaddlePaddle学习Bert_ 一只博客-CSDN博客https://blog.csdn.net/qq_42276781/article/details/121488335【零基础-2】PaddlePaddle学习Bert_ 一只博客-CSDN博客https://blog.csdn.net/qq_42276781/article/details/121523268【零基础-3】PaddlePaddle学习Be…

【零基础-3】PaddlePaddle学习Bert
概要
【零基础-1】PaddlePaddle学习Bert_ 一只博客-CSDN博客https://blog.csdn.net/qq_42276781/article/details/121488335【零基础-2】PaddlePaddle学习Bert_ 一只博客-CSDN博客https://blog.csdn.net/qq_42276781/article/details/121523268
Cell 7
# 创建dataloader
def…

【零基础-1】PaddlePaddle学习Bert
一、准备工作
Bert作为一个近几年兴起的深度学习模型框架,凭借其在多个数据集中state-of-the-art的表现,在自然语言处理(Natural Language Processing, NLP)和计算机视觉(Computer Vision, CV)声名鹊起。 …
文本分类心得(Bert模型使用)
正式入职了一段时间,接手了NLP相关任务,作为一个初学者,分享一点最近的所学心得和体会。
稍后有时间更新,现在项目催的很紧,能力比较强的可以找我内推阿里秋招。可以私信我联系方法,个人会进行第一遍简历筛…
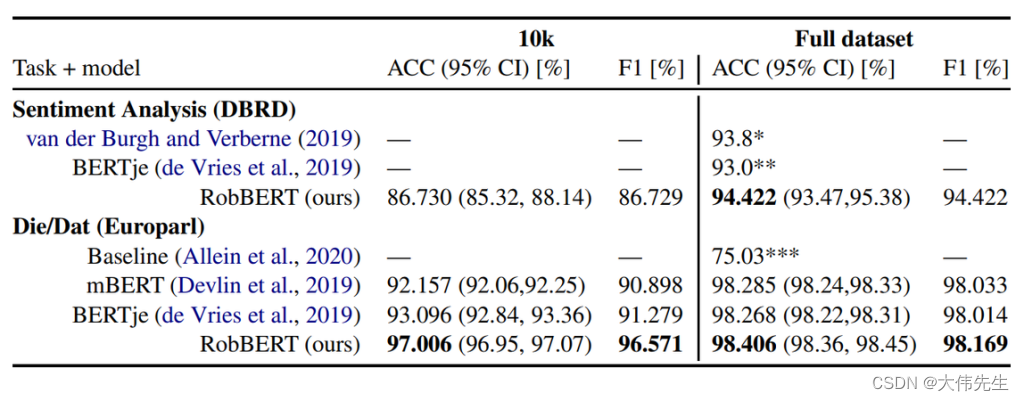
KU Leuven TU Berlin 推出“RobBERT”,一款荷兰索塔 BERT
荷兰语是大约24万人的第一语言,也是近5万人的第二语言,是继英语和德语之后第三大日耳曼语言。来自比利时鲁汶大学和柏林工业大学的一组研究人员最近推出了基于荷兰RoBERTa的语言模型RobBERT。
谷歌的BERT(来自Transformers的B idirectional …
引入BertTokenizer出现OSError: Can‘t load tokenizer for ‘bert-base-uncased‘.
今天在跑一个模型的时候出现该报错,完整报错为:
OSError: Cant load tokenizer for bert-base-uncased. If you were trying to load it from https://huggingface.co/models, make sure you dont have a local directory with the same name. Otherwis…
![[Python人工智能] 四十三.命名实体识别 (4)利用bert4keras构建Bert+BiLSTM-CRF实体识别模型](https://img-blog.csdnimg.cn/bf1659094a5b4541a19a93c14fafa5d1.png#pic_center)
[Python人工智能] 四十三.命名实体识别 (4)利用bert4keras构建Bert+BiLSTM-CRF实体识别模型
从本专栏开始,作者正式研究Python深度学习、神经网络及人工智能相关知识。前文讲解如何实现中文命名实体识别研究,构建BiGRU-CRF模型实现。这篇文章将继续以中文语料为主,介绍融合Bert的实体识别研究,使用bert4keras和kears包来构建Bert+BiLSTM-CRF模型。然而,该代码最终结…
机器学习深度学习——NLP实战(自然语言推断——微调BERT实现)
👨🎓作者简介:一位即将上大四,正专攻机器学习的保研er 🌌上期文章:机器学习&&深度学习——针对序列级和词元级应用微调BERT 📚订阅专栏:机器学习&&深度学习 希望文…

基于深度学习LSTM+NLP情感分析电影数据爬虫可视化分析推荐系统(深度学习LSTM+机器学习双推荐算法+scrapy爬虫+NLP情感分析+数据分析可视化)
文章目录 基于深度学习LSTMNLP情感分析电影数据爬虫可视化分析推荐系统(深度学习LSTM机器学习双推荐算法scrapy爬虫NLP情感分析数据分析可视化)项目概述深度学习长短时记忆网络(Long Short-Term Memory,LSTM)机器学习协…
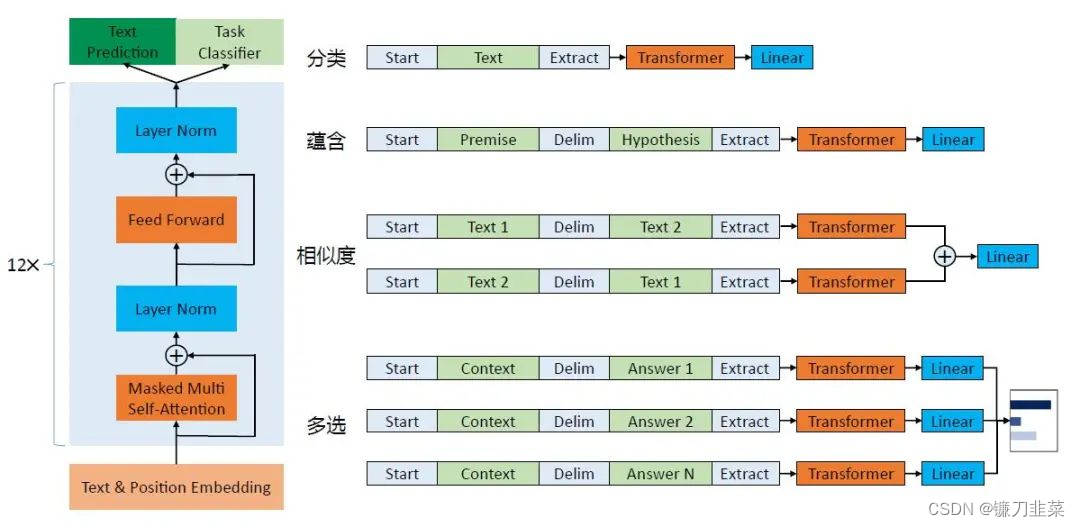
【AI理论学习】语言模型:掌握BERT和GPT模型
语言模型:掌握BERT和GPT模型 BERT模型BERT的基本原理BERT的整体架构BERT的输入BERT的输出 BERT的预训练掩码语言模型预测下一个句子 BERT的微调BERT的特征提取使用PyTorch实现BERT GPT模型GPT模型的整体架构GPT的模型结构GPT-2的Multi-Head与BERT的Multi-Head之间的…
一个基本的BERT模型框架
构建一个完整的BERT模型并进行训练是一个复杂且耗时的任务。BERT模型由多个组件组成,包括嵌入层、Transformer编码器和分类器等。编写这些组件的完整代码超出了文本的范围。然而,一个基本的BERT模型框架以便了解其结构和主要组件的设置。
import torch
…

从统计语言模型到预训练语言模型---预训练语言模型(BERT,GPT,BART系列)
基于 Transformer 架构以及 Attention 机制,一系列预训练语言模型被不断提出。
BERT
2018 年 10 月, Google AI 研究院的 Jacob Devlin 等人提出了 BERT (Bidirectional Encoder Representation from Transformers ) 。具体的研究论文发布在 arXiv …

各种预训练模型的理论和调用方式大全
诸神缄默不语-个人CSDN博文目录
本文主要以模型被提出的时间为顺序,系统性介绍各种预训练模型的理论(尤其是相比之前工作的创新点)、调用方法和表现效果。
最近更新时间:2023.5.10 最早更新时间:2023.5.10
BertRobe…
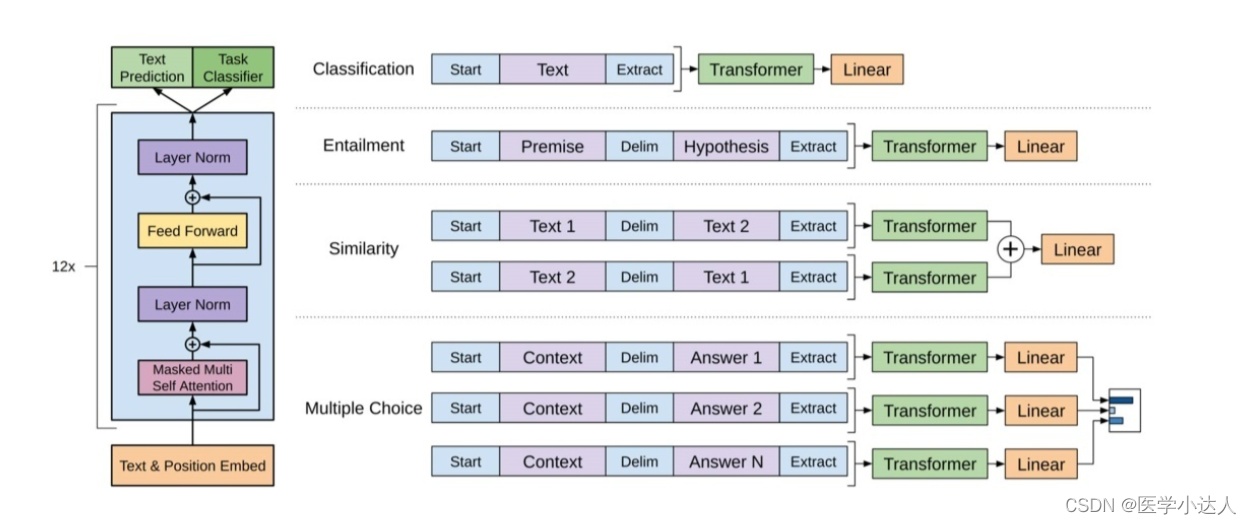
Transformer、Bert、Gpt对比系列,超详细介绍transformer的原理,bert和gpt的区别
一、Transformer架构图
Transformer 是一种用于序列到序列学习的神经网络模型,主要用于自然语言处理任务,如机器翻译、文本摘要等。它在2017年由 Google 提出,采用了注意力机制来对输入序列进行编码和解码。
Transformer 模型由编码器和解码…
bert中文文本摘要代码(3)
bert中文文本摘要代码 写在最前面关于BERT使用transformers库进行微调 train.py自定义参数迭代训练验证评估更新损失绘图主函数 test.pytop_k或top_p采样sample_generate函数generate_file函数主函数 写在最前面
熟悉bert+文本摘要的下游任务微调的代码,…

通俗理解词向量模型,预训练模型,Transfomer,Bert和GPT的发展脉络和如何实践
最近研究GPT,深入的从transfomer的原理和代码看来一下,现在把学习的资料和自己的理解整理一下。
这个文章写的很通俗易懂,把transformer的来龙去脉,还举例了很多不错的例子。
Transformer通俗笔记:从Word2Vec、Seq2S…

使用Pytorch从零开始实现BERT
生成式建模知识回顾: [1] 生成式建模概述 [2] Transformer I,Transformer II [3] 变分自编码器 [4] 生成对抗网络,高级生成对抗网络 I,高级生成对抗网络 II [5] 自回归模型 [6] 归一化流模型 [7] 基于能量的模型 [8] 扩散模型 I, 扩散模型 II…
深度学习(八):bert理解之transformer
1.主要结构
transformer 是一种深度学习模型,主要用于处理序列数据,如自然语言处理任务。它在 2017 年由 Vaswani 等人在论文 “Attention is All You Need” 中提出。
Transformer 的主要特点是它完全放弃了传统的循环神经网络(RNN&#x…
huggingface实战bert-base-chinese模型(训练+预测)
文章目录 前言一、bert模型词汇映射说明二、bert模型输入解读1、input_ids说明2、attention_mask说明3、token_type_ids说明4、模型输入与vocab映射内容二、huggingface模型数据加载1、数据格式查看2、数据dataset处理3、tokenizer处理dataset数据三、huggingface训练bert分类模…
使用PaddleNLP识别垃圾邮件:用BERT做中文邮件内容分类,验证集准确率高达99.6%以上(附公开数据集)
使用PaddleNLP识别垃圾邮件:用BERT做中文邮件内容分类,验证集准确率高达99.6%以上(附公开数据集)。
要使用PaddleNLP和BERT来识别垃圾邮件并做中文邮件内容分类,可以按照以下步骤进行操作: 安装PaddlePaddle和PaddleNLP:首先,确保在你的环境中已经安装了PaddlePaddle和…
Transformers微调BERT模型实现文本分类任务(colab)
1. 数据准备
使用colab进行实验
左上角上传数据,到当前实验室 右上角设置GPU选择
查看GPU
! nvidia-sm安装需要的库
!pip install datasets
!pip install transformers[torch]
!pip install torchkeras1.1 读取数据
import pandas as pd
data pd.read_csv(&…
LLM - Hugging Face 工程 BERT base model (uncased) 配置
欢迎关注我的CSDN:https://spike.blog.csdn.net/ 本文地址:https://blog.csdn.net/caroline_wendy/article/details/131400428 BERT是一个在大量英文数据上以自监督的方式预训练的变换器模型。这意味着它只是在原始文本上进行预训练,没有人以…

【论文精读】BERT
摘要 以往的预训练语言表示应用于下游任务时的策略有基于特征和微调两种。其中基于特征的方法如ELMo使用基于上下文的预训练词嵌入拼接特定于任务的架构;基于微调的方法如GPT使用未标记的文本进行预训练,并针对有监督的下游任务进行微调。 但上述两种策略…
Bert基础(一)--自注意力机制
1、简介
当下最先进的深度学习架构之一,Transformer被广泛应用于自然语言处理领域。它不单替代了以前流行的循环神经网络(recurrent neural network, RNN)和长短期记忆(long short-term memory, LSTM)网络,并且以它为基础衍生出了诸如BERT、GPT-3、T5等…
Bert基础(四)--解码器(上)
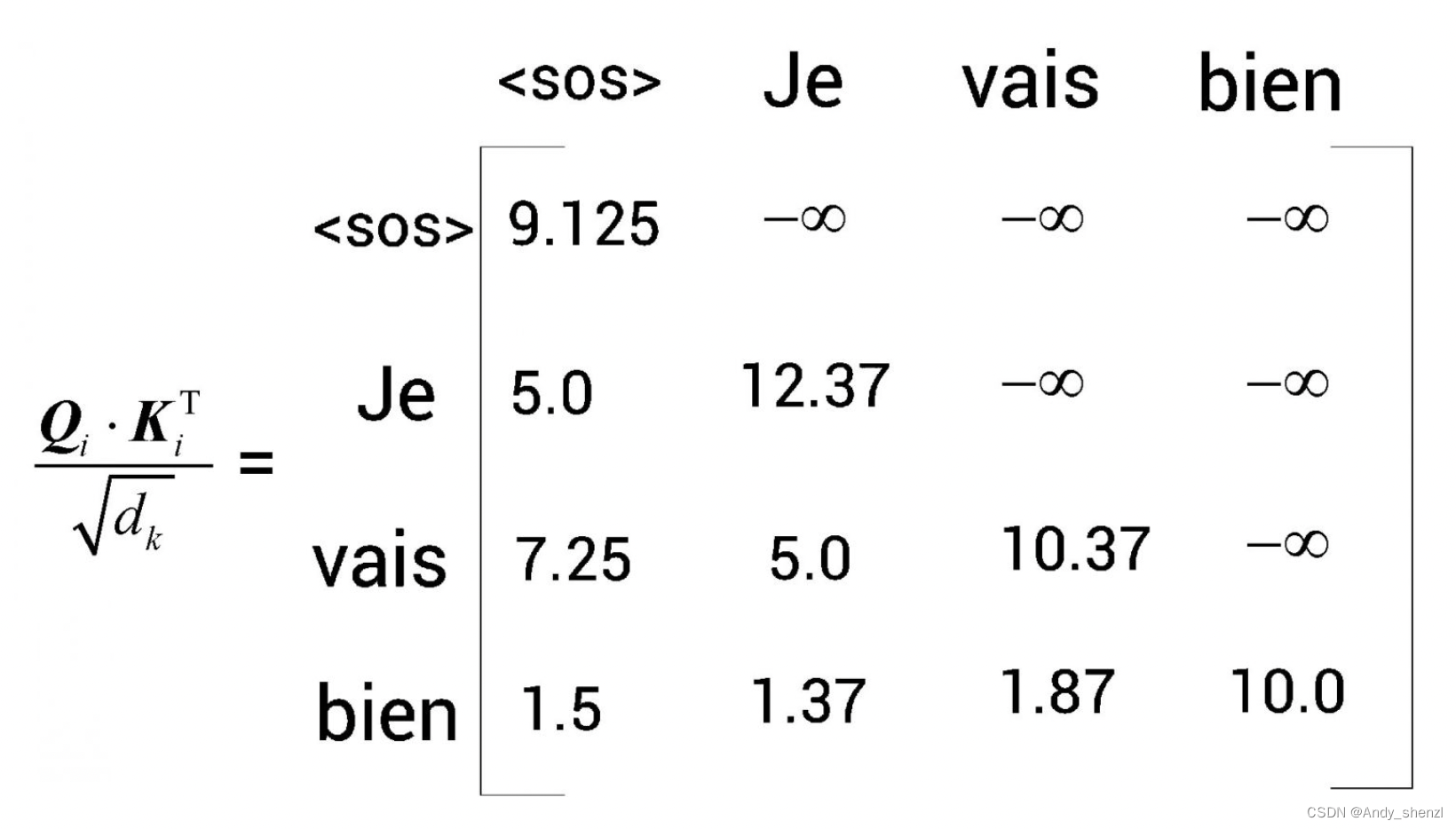
1 理解解码器
假设我们想把英语句子I am good(原句)翻译成法语句子Je vais bien(目标句)。首先,将原句I am good送入编码器,使编码器学习原句,并计算特征值。在前文中,我们学习了编…
BERT:基于TensorFlow的BERT模型搭建中文问答任务模型
目录 1、导入依赖库2、准备数据集3、对问题和答案进行分词4、构建模型5、编译模型6、训练模型7、评估模型8、使用模型进行预测 1、导入依赖库
#导入numpy库,用于进行数值计算
import numpy as np#从Keras库中导入Tokenizer类,用于将文本转换为序列
from…
BERT:深度学习领域中的语言理解利器
BERT:深度学习领域中的语言理解利器
摘要
BERT(双向编码器表示法自转换器)是一种领先的深度学习模型,它在许多语言理解任务中都显示出卓越的性能。BERT模型基于转换器编码器架构,并通过自监督学习在大量未标记文本数…
![[oneAPI] 基于BERT预训练模型的SWAG问答任务](https://img-blog.csdnimg.cn/e7c43f8f78b645a2ab118e73b97b6bb8.png)
[oneAPI] 基于BERT预训练模型的SWAG问答任务
[oneAPI] 基于BERT预训练模型的SWAG问答任务 基于Intel DevCloud for oneAPI下的Intel Optimization for PyTorch基于BERT预训练模型的SWAG问答任务数据集下载和描述数据集构建问答选择模型训练 结果参考资料 比赛:https://marketing.csdn.net/p/f3e44fbfe46c465f4d…

【NLP笔记】预训练+微调范式之OpenAI Transformer、ELMo、ULM-FiT、Bert..
文章目录 OpenAI TransformerELMoULM-FiTBert基础结构Embedding预训练&微调 【原文链接】:
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding 【本文参考链接】
The Illustrated BERT, ELMo, and co. (How NLP Cracked Tra…
huggingface的transformers训练bert
目录
理论
实践 理论
https://arxiv.org/abs/1810.04805 BERT(Bidirectional Encoder Representations from Transformers)是一种自然语言处理(NLP)模型,由Google在2018年提出。它是基于Transformer模型的预训练方法…

bert 相似度任务训练,简单版本
目录
任务
代码
train.py
predit.py
数据 任务
使用 bert-base-chinese 训练相似度任务,参考:微调BERT模型实现相似性判断 - 知乎
参考他上面代码,他使用的是 BertForNextSentencePrediction 模型,BertForNextSentencePred…
多模态学习 - 视觉语言预训练综述-2023-下游任务、数据集、基础知识、预训练任务、模型
参考: https://zhuanlan.zhihu.com/p/628840228 https://zhuanlan.zhihu.com/p/628994098 https://zhuanlan.zhihu.com/p/629996372 https://zhuanlan.zhihu.com/p/582424974 多模态学习 - 视觉语言预训练综述-2023-下游任务、数据集、基础知识、模型 1. 多模态介绍…
Bert基础(九)--Bert变体之ALBERT
在接下来的几篇,我们将了解BERT的不同变体,包括ALBERT、RoBERTa、ELECTRA和SpanBERT。我们将首先了解ALBERT。ALBERT的英文全称为A Lite version of BERT,意思是BERT模型的精简版。ALBERT模型对BERT的架构做了一些改变,以尽量缩短…
【深度学习】BERT变体—SpanBERT
SpanBERT出自Facebook,就是在BERT的基础上,针对预测spans of text的任务,在预训练阶段做了特定的优化,它可以用于span-based pretraining。这里的Span翻译为“片段”,表示一片连续的单词。SpanBERT最常用于需要预测文本…

Extractive Summarization as Text Matching论文学习
一、总结 代码:https://github.com/maszhongming/MatchSum 感觉论文讲的不清不楚的啊,一头雾水。
后面可以看下这个 BERTSUM论文笔记:https://zhuanlan.zhihu.com/p/264184125 BERT时代下的摘要提取长文总结:https://zhuanlan.z…
深入理解深度学习——BERT派生模型:RoBERTa(A Robustly Optimized BERT Pretraining Approach)
分类目录:《深入理解深度学习》总目录 现阶段,预训练语言模型总是可以通过更大的模型和更多的数据获得更好的性能,GPT系列模型就是此类优化方向的典范。RoBERTa(模型名源自论文名A Robustly Optimized BERT Pretraining Approach&…

用可视化解构BERT,我们从上亿参数中提取出了6种直观模式
作者: 龙心尘 时间:2019年1月 出处:https://blog.csdn.net/longxinchen_ml/article/details/89036531
大数据文摘联合百度NLP出品 审校:百度NLP、龙心尘 编译:Andy,张驰 来源:towardsdatascien…
【文本到上下文 #9】NLP中的BERT和迁移学习
一、说明 BERT:适合所有人的架构概述:我们将分解 BERT 的核心组件,解释该模型如何改变机器理解人类语言的方式,以及为什么它比以前的模型有重大进步。 BERT的变体: 在BERT取得成功之后,已…

自然语言处理(七):来自Transformers的双向编码器表示(BERT)
来自Transformers的双向编码器表示(BERT)
BERT(Bidirectional Encoder Representations from Transformers)是一种预训练的自然语言处理模型,由Google于2018年提出。它是基于Transformer模型架构的深度双向࿰…
【动手学深度学习-Pytorch版】BERT预测系列——用于预测的BERT数据集
本小节的主要任务即是将wiki数据集转成BERT输入序列,具体的任务包括:
读取wiki数据集生成下一句预测任务的数据—>主要用于_get_nsp_data_from_paragraph函数从输入paragraph生成用于下一句预测的训练样本:_get_nsp_data_from_paragraph生…
基于Bert+对抗训练的文本分类实现
由于Bert的强大,它文本分类取得了非常好的效果,而通过对抗训练提升模型的鲁棒性是一个非常有研究意义的方向,下面将通过代码实战与大家一起探讨交流对抗训练在Bert文本分类领域的应用。
目录
一、Bert文本分类在input_ids添加扰动
二、Ber…

【自注意力机制必学】BERT类预训练语言模型(含Python实例)
BERT类预训练语言模型 文章目录 BERT类预训练语言模型1. BERT简介1.1 BERT简介及特点1.2 传统方法和预训练方法1.3 BERT的性质 2. BERT结构2.1 输入层以及位置编码2.2 Transformer编码器层2.3 前馈神经网络层2.4 残差连接层2.5 输出层 3. BERT类模型简要笔记4. 代码工程实践 1.…

Bert基础(二)--多头注意力
多头注意力
顾名思义,多头注意力是指我们可以使用多个注意力头,而不是只用一个。也就是说,我们可以应用在上篇中学习的计算注意力矩阵Z的方法,来求得多个注意力矩阵。让我们通过一个例子来理解多头注意力层的作用。以All is well…
本地训练,开箱可用,Bert-VITS2 V2.0.2版本本地基于现有数据集训练(原神刻晴)
按照固有思维方式,深度学习的训练环节应该在云端,毕竟本地硬件条件有限。但事实上,在语音识别和自然语言处理层面,即使相对较少的数据量也可以训练出高性能的模型,对于预算有限的同学们来说,也没必要花冤枉…

基于Bert的知识库智能问答系统
项目完整地址: 可以先看一下Bert的介绍。 Bert简单介绍
一.系统流程介绍。 知识库是指存储大量有组织、有结构的知识和信息的仓库。这些知识和信息被存储为实体和实体关系的形式,通常用于支持智能问答系统。在一个知识库中,每个句子通常来说…

NLP(六十七)BERT模型训练后动态量化(PTDQ)
本文将会介绍BERT模型训练后动态量化(Post Training Dynamic Quantization,PTDQ)。
量化 在深度学习中,量化(Quantization)指的是使用更少的bit来存储原本以浮点数存储的tensor,以及使用更少的…
Transformers BERT GPT T5 一本书精通
2022新书 Natural Language Processing with Transformers (中译本) 点击以上链接访问,完全免费开放。
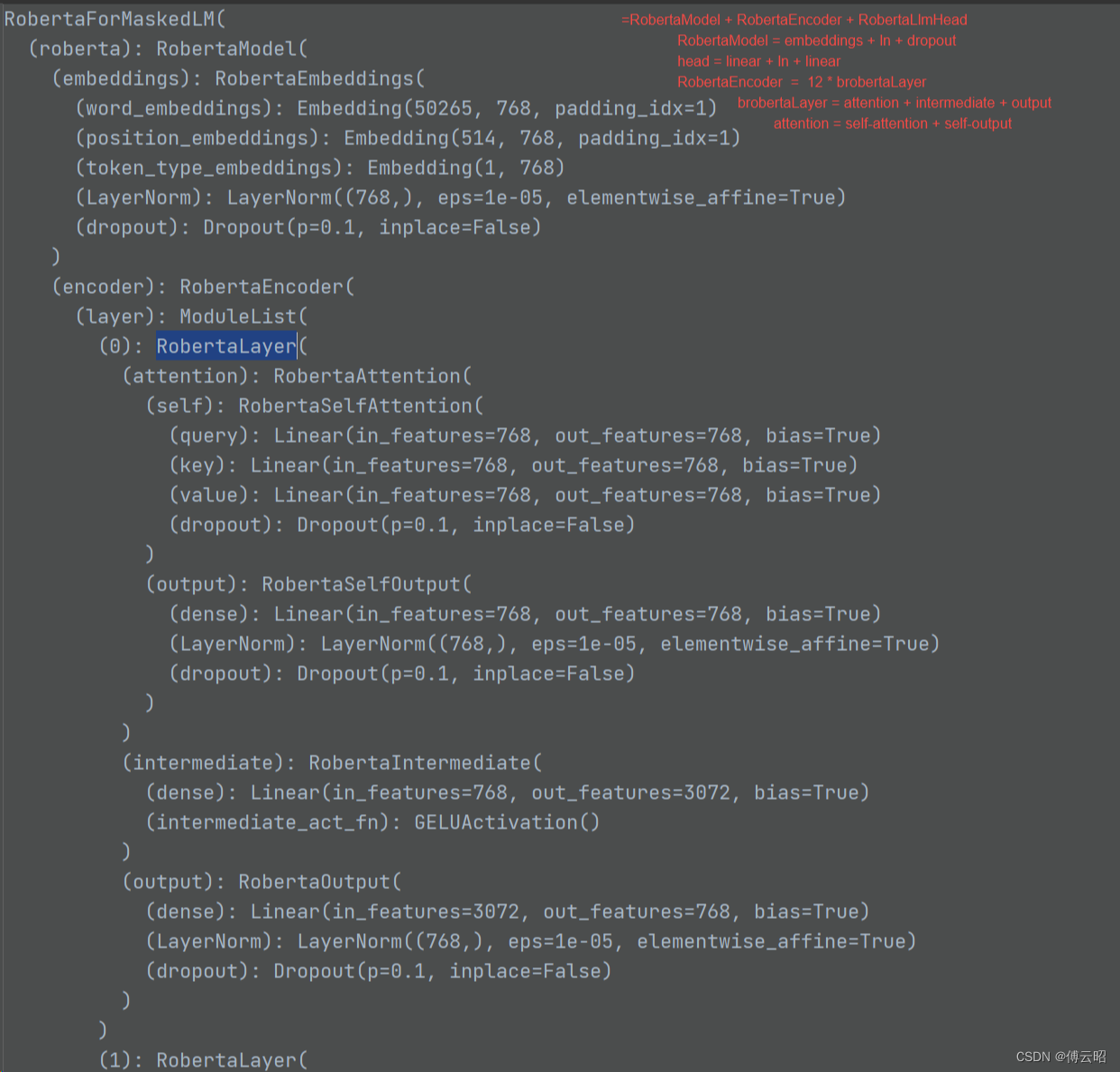
BERT模型结构可视化与模块维度转换剖析
大家好,我是herosunly。985院校硕士毕业,现担任算法研究员一职,热衷于机器学习算法研究与应用。曾获得阿里云天池比赛第一名,科大讯飞比赛第三名,CCF比赛第四名。拥有多项发明专利。对机器学习和深度学习拥有自己独到的见解。曾经辅导过若干个非计算机专业的学生进入到算法…
使用Bert,ERNIE,进行中文文本分类
GitHub - 649453932/Bert-Chinese-Text-Classification-Pytorch: 使用Bert,ERNIE,进行中文文本分类使用Bert,ERNIE,进行中文文本分类. Contribute to 649453932/Bert-Chinese-Text-Classification-Pytorch development by creatin…
图解Transformer(完整版)
作者: 龙心尘 时间:2019年1月 出处:https://blog.csdn.net/longxinchen_ml/article/details/86533005
审校:百度NLP、龙心尘 翻译:张驰、毅航、Conrad 原作者:Jay Alammar 原链接:https://jala…
基于BERT模型进行文本处理(Python)
基于BERT模型进行文本处理(Python)
所有程序都由Python使用Spyder运行。 对于BERT,在运行之前,它需要安装一些环境。 首先,打开Spyder。其次,在控制台中单独放置要安装的:
pip install transformers
pip install tor…
Bert pytorch 版本解读 之 Bert pretraining 中mask的实现
BERT Mask 方法
从Bert 论文中,我们可以知道BERT在pretrain的时候 会对训练集进行MASK 操作, 其中mask的方法是:
15%的原始数据被mask, 85% 没有被mask.对于被mask的15% 分3种处理方式: 1) 其中80%是赋值为MASK. 2) 10%进行random 赋值,3)剩下10%保留原来值.
伯努利函数
在…
NLP:bert下载与使用
没办法,模型精度还是不够,只能暂时弃用text2vec。然后我在github上发现了中文文本处理的老大哥:bert
python使用bert可以参考这篇博客:博客
但是篇博客又出现了上一节的问题: We couldnt connect to https://hugging…
NLP(六十六)使用HuggingFace中的Trainer进行BERT模型微调
以往,我们在使用HuggingFace在训练BERT模型时,代码写得比较复杂,涉及到数据处理、token编码、模型编码、模型训练等步骤,从事NLP领域的人都有这种切身感受。事实上,HugggingFace中提供了datasets模块(数据处…
如何在脱敏数据中使用BERT等预训练模型
前几天有朋友问了一下【小布助手短文本语义匹配竞赛】的问题,主要是两个;
如何在脱敏数据中使用BERT;基于此语料如何使用NSP任务;
比赛我没咋做,因为我感觉即使认真做也打不过前排大佬[囧],太菜了&#x…
【零基础-2】PaddlePaddle学习Bert
概要
【零基础-1】PaddlePaddle学习Bert_ 一只博客-CSDN博客https://blog.csdn.net/qq_42276781/article/details/121488335
Cell 3
# 调用bert模型用的tokenizer
tokenizer ppnlp.transformers.BertTokenizer.from_pretrained(bert-base-chinese)
inputs_1 tokenizer(今天…
【AI实战】BERT 文本分类模型自动化部署之 dockerfile
【AI实战】BERT 文本分类模型自动化部署之 dockerfile BERTBERT 文本分类模型基于中文预训练bert的文本分类模型针对多分类模型的loss函数样本不均衡时多标签分类时 dockerfile编写 dockerfilebuild镜像运行docker测试服务 参考 本文主要介绍:
基于BERT的文本分类模…
【视频】超越BERT的最强中文NLP预训练模型艾尼ERNIE官方揭秘
分章节视频链接:http://abcxueyuan.cloud.baidu.com/#/course_detail?id15076&courseId15076完整视频链接:http://play.itdks.com/watch/8591895
艾尼(ERNIE)是目前NLP领域的最强中文预训练模型。
百度资深研发工程师龙老师…

自然语言处理(八):预训练BERT
来自Transformers的双向编码器表示(BERT)
BERT(Bidirectional Encoder Representations from Transformers)是一种预训练的自然语言处理模型,由Google于2018年提出。它是基于Transformer模型架构的深度双向࿰…
paper 阅读 - BERT: Pre-training of Deep Bidirectional Transformers forLanguage Understanding
目录
1 BERT VS Transformer
1.1 图示
1.2 输入
1.3 模型
1.4 任务
1.4.1 BERT 预训练
1.5 附录待续 论文发布于2019
1 BERT VS Transformer
1.1 图示
Transformer BERT 1.2 输入
Transformer: 位置 encoder token embedding,在训练的时候 …
来自Transformers的双向编码器表示(BERT)
word2vec和GloVe等词嵌入模型与上下文无关。它们将相同的预训练向量赋给同一个词,而不考虑词的上下文(如果有的话)。它们很难处理好自然语言中的一词多义或复杂语义。 对于上下文敏感的词表示,如ELMo和GPT,词的表示依…
从零开始复现BERT,并进行预训练和微调
从零开始复现BERT
代码地址:https://gitee.com/guojialiang2023/bert
模型
BERT 是一种基于 Transformer 架构的大型预训练模型,它通过学习大量文本数据来理解语言的深层次结构和含义,从而在各种 NLP 任务中实现卓越的性能。
核心的 BER…

bert,transformer架构图及面试题
Transformer详解 - mathor atten之后经过一个全连接层残差层归一化 class BertSelfOutput(nn.Module):def __init__(self, config):super().__init__()self.dense nn.Linear(config.hidden_size, config.hidden_size)self.LayerNorm nn.LayerNorm(config.hidden_size, epscon…

BEiT: BERT Pre-Training of Image Transformers 论文笔记
BEiT: BERT Pre-Training of Image Transformers 论文笔记
论文名称:BEiT: BERT Pre-Training of Image Transformers
论文地址:2106.08254] BEiT: BERT Pre-Training of Image Transformers (arxiv.org)
代码地址:unilm/beit at master …
【NLP】1、BERT | 双向 transformer 预训练语言模型
文章目录 一、背景二、方法 论文:BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
出处:Google
一、背景
在 BERT 之前的语言模型如 GPT 都是单向的模型,但 BERT 认为虽然单向(从左到右预测…
![[oneAPI] 基于BERT预训练模型的英文文本蕴含任务](https://img-blog.csdnimg.cn/4affc2f77e684260aeedb0e0a5e1d888.png)
[oneAPI] 基于BERT预训练模型的英文文本蕴含任务
[oneAPI] 基于BERT预训练模型的英文文本蕴含任务 Intel DevCloud for oneAPI 和 Intel Optimization for PyTorch基于BERT预训练模型的英文文本蕴含任务语料介绍数据集构建 模型训练 结果参考资料 比赛:https://marketing.csdn.net/p/f3e44fbfe46c465f4d9d6c23e38e0…
Bert-vits2-2.3-Final,Bert-vits2最终版一键整合包(复刻生化危机艾达王)
近日,Bert-vits2发布了最新的版本2.3-final,意为最终版,修复了一些已知的bug,添加基于 WavLM 的 Discriminator(来源于 StyleTTS2),令人意外的是,因情感控制效果不佳,去除…
![[RoBERTa]论文实现:RoBERTa: A Robustly Optimized BERT Pretraining Approach](https://img-blog.csdnimg.cn/direct/0784bd8fbe274ebdb0c271aa94984dad.png)
[RoBERTa]论文实现:RoBERTa: A Robustly Optimized BERT Pretraining Approach
文章目录 一、完整代码二、论文解读2.1 模型架构2.2 参数设置2.3 数据2.4 评估 三、对比四、整体总结 论文:RoBERTa:A Robustly Optimized BERT Pretraining Approach 作者:Yinhan Liu, Myle Ott, Naman Goyal, Jingfei Du, Mandar Joshi, Da…
NLP之Bert多分类实现案例(数据获取与处理)
文章目录 1. 代码解读1.1 代码展示1.2 流程介绍1.3 debug的方式逐行介绍 3. 知识点 1. 代码解读
1.1 代码展示
import json
import numpy as np
from tqdm import tqdmbert_model "bert-base-chinese"from transformers import AutoTokenizertokenizer AutoToken…
bert ranking pairwise demo
下面是用bert 训练pairwise rank 的 demo
import torch
from torch.utils.data import DataLoader, Dataset
from transformers import BertModel, BertTokenizer
from sklearn.metrics import pairwise_distances_argmin_minclass PairwiseRankingDataset(Dataset):def __ini…
Bert-vits2-v2.2新版本本地训练推理整合包(原神八重神子英文模型miko)
近日,Bert-vits2-v2.2如约更新,该新版本v2.2主要把Emotion 模型换用CLAP多模态模型,推理支持输入text prompt提示词和audio prompt提示语音来进行引导风格化合成,让推理音色更具情感特色,并且推出了新的预处理webuI&am…
bert_base_chinese入门
import torch from transformers import AutoTokenizer, AutoModelForMaskedLM model_name"bert-base-chinese" tokenizer AutoTokenizer.from_pretrained(model_name) # 带有语言模型头的模型 model AutoModelForMaskedLM.from_pretrained(model_name)
input_tex…
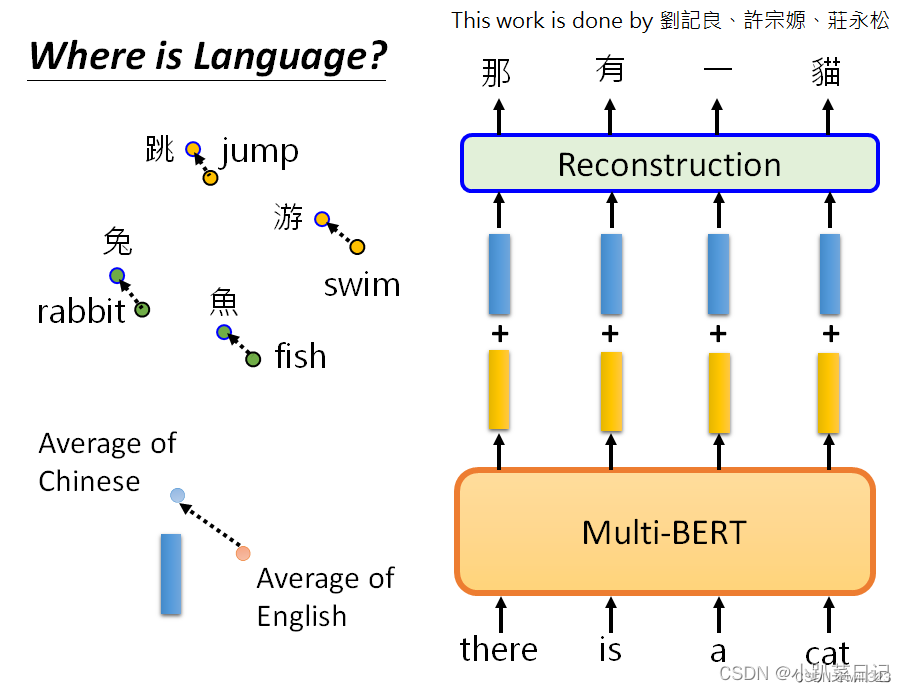
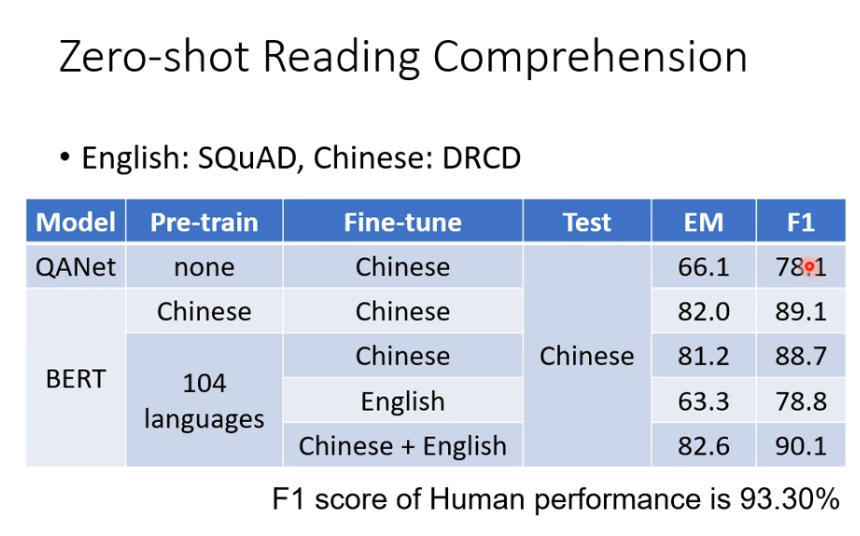
机器学习:自督导式学习模型
outline 自督导式模型有跨语言的能力 中文:DRCD的数据集英文:SQuAD的数据集 在104种语言上进行学习,并在英文上进行微调,结果在中文上效果也比较好。 XTREME Benchmark 只用英文进行微调,在其他剩下的语言中进行测试。…
[论文笔记]Sentence-BERT[v2]
引言
本文是SBERT(Sentence-BERT)论文1的笔记。SBERT主要用于解决BERT系列模型无法有效地得到句向量的问题。很久之前写过该篇论文的笔记,但不够详细,今天来重新回顾一下。
BERT系列模型基于交互式计算输入两个句子之间的相似度是非常低效的(但效果是很好的)。当然可以通过…
云端开炉,线上训练,Bert-vits2-v2.2云端线上训练和推理实践(基于GoogleColab)
假如我们一定要说深度学习入门会有一定的门槛,那么设备成本是一个无法避开的话题。深度学习模型通常需要大量的计算资源来进行训练和推理。较大规模的深度学习模型和复杂的数据集需要更高的计算能力才能进行有效的训练。因此,训练深度学习模型可能需要使…

近80%企业首选——亚马逊云科技为中国企业出海保驾护航
随着全球数字化进程的不断加速,中国出海“大航海时代”已然到来。从#万企组团出国抢订单#到#苏州赴日包机抢单20亿元#,中国企业对海外市场的优势已经一步步建立了起来。
从卖小商品、卖鞋的“世界工厂”,到现在产业升级后的卖汽车、卖服务、…
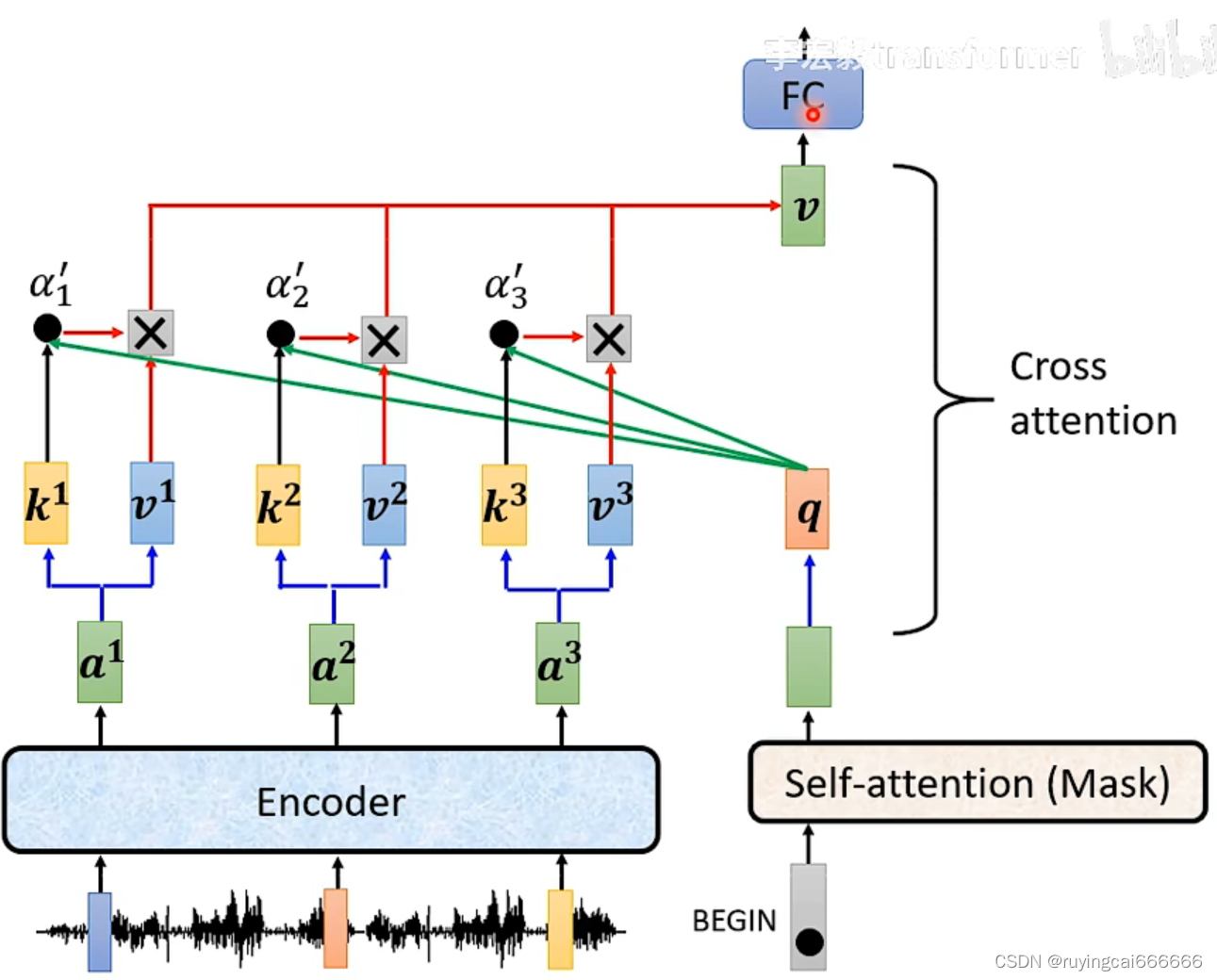
self-attention、transformer、bert理解
参考李宏毅老师的视频 https://www.bilibili.com/video/BV1LP411b7zS?p2&spm_id_frompageDriver&vd_sourcec67a2725ac3ca01c38eb3916d221e708 一个输入,一个输出,未考虑输入之间的关系!!!
self-attention…
ChineseBERT使用指北
文章目录 ChineseBert 模型介绍开源代码使用方法未完待续 ChineseBert 模型介绍
论文地址:https://arxiv.org/pdf/2106.16038.pdf 代码地址:https://github.com/ShannonAI/ChineseBert
bert是语义模型,因此无法解决形近字、音近字的问题。 …
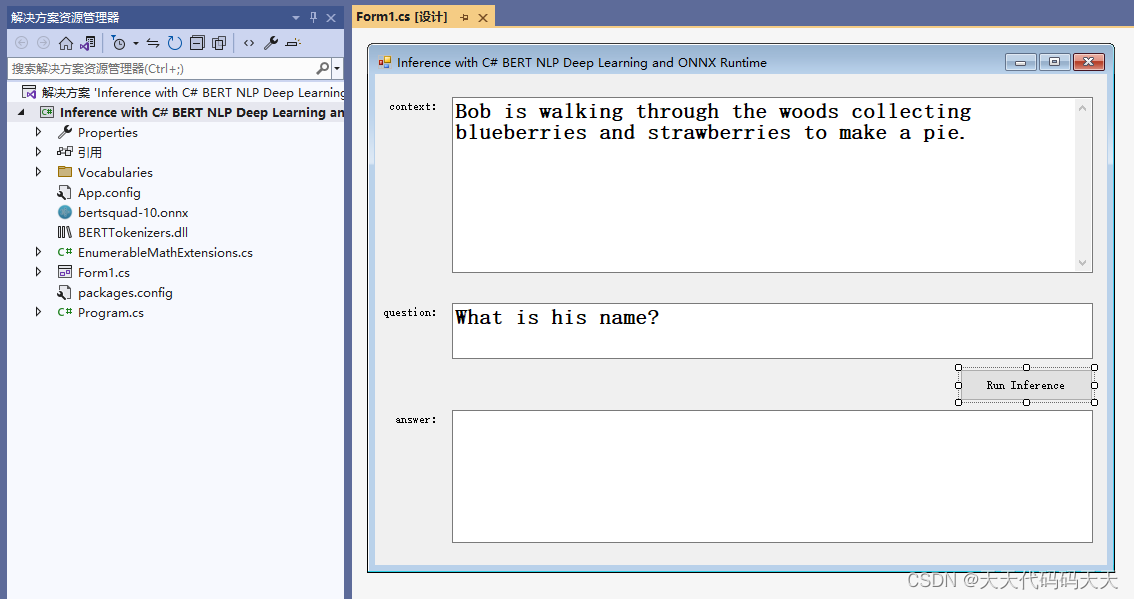
Inference with C# BERT NLP Deep Learning and ONNX Runtime
目录
效果
测试一
测试二
测试三
模型信息
项目
代码
下载 Inference with C# BERT NLP Deep Learning and ONNX Runtime
效果
测试一
Context :Bob is walking through the woods collecting blueberries and strawberries to make a pie.
Question …

bert+np.memap+faiss文本相似度匹配 topN
目录
任务
代码
结果说明 任务
使用 bert-base-chinese 预训练模型将文本数据向量化后,使用 np.memap 进行保存,再使用 faiss 进行相似度匹配出每个文本与它最相似的 topN
此篇文章使用了地址数据,目的是为了跑通这个流程,数…
Kaggle - LLM Science Exam上:赛事概述、数据收集、BERT Baseline
文章目录 一、赛事概述1.1 OpenBookQA Dataset1.2 比赛背景1.3 评估方法和代码要求1.4 比赛数据集1.5 优秀notebook 二、BERT Baseline2.1 数据预处理2.2 定义data_collator2.3 加载模型,配置trainer并训练2.4 预测结果并提交2.5 deberta-v3-large 1k Wikiÿ…
Bert-as-service 学习
pip3 install --user --upgrade tensorflow
安装遇到的问题如下:
pip3 install --user --upgrade tensorflow 1052 pip uninstall protobuf 1053 pip3 uninstall protobuf 1054 pip3 install protobuf3.20.* 1055 pip3 install open-clip-torch2.8.2 1…
【深度学习】BERT是什么?怎么玩的?
RNN
也是一种Seq2Seq网络 这种RNN就不能并行运算,且对于长句子会造成损失遗忘或者梯度爆炸
Transfomer
Transformer由且仅由self-Attenion和Feed Forward Neural Network组成。一个基于Transformer的可训练的神经网络可以通过堆叠Transformer的形式进行搭建&…

基于BERT的自然语言处理垃圾邮件检测模型
❤️觉得内容不错的话,欢迎点赞收藏加关注😊😊😊,后续会继续输入更多优质内容❤️👉有问题欢迎大家加关注私戳或者评论(包括但不限于NLP算法相关,linux学习相关,读研读博…

开源项目_BERT_意图分类与槽填充
项目地址:GitHub - taishan1994/pytorch_bert_intent_classification_and_slot_filling: 基于pytorch的中文意图识别和槽位填充
项目运行:
1、#按照readme要求创建环境
conda create pytorch transformers python3.7.02、提示缺少seqeval包
pip instal…
one-hot到word2vec到bert的进化史(待完善)
本文还是一篇不讲具体原理细节的博客,只写一些3者之间的区别优劣问题,建议先搞懂原理再看,有疑问或者有新的见解,欢迎留言提出。
word2vec和embedding梳理
1. 从one-hot开始
优点:一是解决了分类器不好处理离散数据…
bert源码分析之tokenization
import collections# 集合模块 import re# 正则模块 import unicodedata#判断字符类别模块 import six#判断版本 import tensorflow as tf # 用于检查传入的参数do_lower_case和真正的模型是否一致 # do_lower_case: 一个布尔值,表示是否将文本转换为小写 # init_ch…
Bert与ChatGPT
1. Bert模型
BERT(Bidirectional Encoder Representations from Transformers)是一种预训练语言表示的方法,由Google AI在2018年提出。它标志着自然语言处理(NLP)领域的一个重大进步,因为它能够理解单词在…
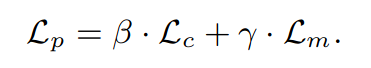
论文阅读_音频表示_W2V-BERT
信息
number headings: auto, first-level 2, max 4, _.1.1 name_en: w2v-BERT: Combining Contrastive Learning and Masked Language Modeling for Self-Supervised Speech Pre-Training name_ch: W2V-BERT:结合对比学习和Mask语言建模进行自监督语音预训练 pape…
【使用 BERT 的问答系统】第 3 章 :词嵌入介绍
🔎大家好,我是Sonhhxg_柒,希望你看完之后,能对你有所帮助,不足请指正!共同学习交流🔎 📝个人主页-Sonhhxg_柒的博客_CSDN博客 📃 🎁欢迎各位→点赞…

快速上手Pytorch实现BERT,以及BERT后接CNN/LSTM
快速上手Pytorch实现BERT,以及BERT后接CNN/LSTM
本项目采用HuggingFace提供的工具实现BERT模型案例,并在BERT后接CNN、LSTM等 HuggingFace官网
一、实现BERT(后接线性层)
1.引用案例源码:
from transformers impo…
ICLR2023 | Mole-BERT: 对分子GNN预训练的反思
原文标题:MOLE-BERT: RETHINKING PRE-TRAINING GRAPH NEURAL NETWORKS FOR MOLECULES
原文链接:Mole-BERT: Rethinking Pre-training Graph Neural Networks for Molecules | OpenReview
https://github.com/junxia97/Mole-BERT
一、Introduction
At…
深入理解深度学习——BERT(Bidirectional Encoder Representations from Transformers):基础知识
分类目录:《深入理解深度学习》总目录 BERT全称为Bidirectional Encoder Representations from Transformers,即来自Transformers的双向编码器表示,是谷歌发表的论文Pre-training of Deep Bidirectional Transformers for Language Understan…
提示学习,transformers/bert中处理 模板 additional-special-tokens
我们在提示学习或其它方式中经常需要对模板中的占位符,如 This is a demon, [X], it was a [MASK] 中的[X]进行替换并需要在随后的处理中取出它对应的向量。 此时,我们需要知道[X]所在的postion, 即偏移才可以正常处理。在transformers中,这个…

Bert机器问答模型QA(阅读理解)
Github参考代码:https://github.com/edmondchensj/ChineseQA-with-BERT
https://zhuanlan.zhihu.com/p/333682032
数据集来源于DuReader Dataset,即百度经验上的问答,在上述链接中提供下载方式。
感谢作者提供的代码。
1、数据集处理
&a…

基于transformers BERT预训练模型问答系统(农行知道)
农行知道问答系统
该项目是基于 hunggingface transformers BertSequenceClassification 模型, 使用BERT中文预训练模型,进行训练.
模型源码可以参考我的github: QABot
模型使用和结果 BERT 中文预训练模型和数据集可以从百度云盘下载 pytorch_model.bin 提取码: y7t6 其中,…
BERT等复杂深度学习模型加速推理方法——模型蒸馏
参考《Distilling the Knowledge in a Neural Network》Hinton等
蒸馏的作用
首先,什么是蒸馏,可以做什么?
正常来说,越复杂的深度学习网络,例如大名鼎鼎的BERT,其拟合效果越好,但伴随着推理…

【变形金刚02】注意机制以及BERT 和 GPT
一、说明 我已经解释了什么是注意力机制,以及与转换器相关的一些重要关键字和块,例如自我注意、查询、键和值以及多头注意力。在这一部分中,我将解释这些注意力块如何帮助创建转换器网络,注意、自我注意、多头注意、蒙面多头注意力…
读书笔记:多Transformer的双向编码器表示法(Bert)-2
多Transformer的双向编码器表示法
Bidirectional Encoder Representations from Transformers,即Bert;
第2章 了解Bert模型(掩码语言模型构建和下句预测)
文本嵌入模型Bert,在许多自然语言处理任务上表现优秀&#…

栩栩如生,音色克隆,Bert-vits2文字转语音打造鬼畜视频实践(Python3.10)
诸公可知目前最牛逼的TTS免费开源项目是哪一个?没错,是Bert-vits2,没有之一。它是在本来已经极其强大的Vits项目中融入了Bert大模型,基本上解决了VITS的语气韵律问题,在效果非常出色的情况下训练的成本开销普通人也完全…
AIGC:使用bert_vits2实现栩栩如生的个性化语音克隆
1 VITS2模型
1.1 摘要
单阶段文本到语音模型最近被积极研究,其结果优于两阶段管道系统。以往的单阶段模型虽然取得了较大的进展,但在间歇性非自然性、计算效率、对音素转换依赖性强等方面仍有改进的空间。本文提出VITS2,一种单阶段的文本到…
![NLP文本匹配任务Text Matching [有监督训练]:PointWise(单塔)、DSSM(双塔)、Sentence BERT(双塔)项目实践](https://img-blog.csdnimg.cn/img_convert/155097bc963b24648129c24d307f4547.png)
NLP文本匹配任务Text Matching [有监督训练]:PointWise(单塔)、DSSM(双塔)、Sentence BERT(双塔)项目实践
NLP文本匹配任务Text Matching [有监督训练]:PointWise(单塔)、DSSM(双塔)、Sentence BERT(双塔)项目实践
0 背景介绍以及相关概念
本项目对3种常用的文本匹配的方法进行实现:Poin…

bert中的数据输入制作data_generate
数据生成器(自动生成训练、验证、测试集)1.需要创建一个类data_generator,这个类继承DataGenerator类(bert4kreas.snippets)这个类主要是做数据生成的迭代器2. 创建 DateProcess() 类:3.测试‘’’ 这的数据…

Briefings in Bioinformatics2021 | Bert-Protein+:基于Bert的抗菌肽识别
论文标题:A novel antibacterial peptide recognition algorithm based on BERT
论文地址:novel antibacterial peptide recognition algorithm based on BERT | Briefings in Bioinformatics | Oxford Academic
代码:https://github.com/B…

基于Bert+Attention+LSTM智能校园知识图谱问答推荐系统——NLP自然语言处理算法应用(含Python全部工程源码及训练模型)+数据集
目录 前言总体设计系统整体结构图系统流程图 运行环境Python 环境服务器环境 模块实现1. 构造数据集2. 识别网络3. 命名实体纠错4. 检索问题类别5. 查询结果 系统测试1. 命名实体识别网络测试2. 知识图谱问答系统整体测试 工程源代码下载其它资料下载 前言
这个项目充分利用了…
用 TripletLoss 优化bert ranking
下面是 用 TripletLoss 优化bert ranking 的demo import torch
from torch.utils.data import DataLoader, Dataset
from transformers import BertModel, BertTokenizer
from sklearn.metrics.pairwise import pairwise_distancesclass TripletRankingDataset(Dataset):def __…
声音克隆,定制自己的声音,使用最新版Bert-VITS2的云端训练+推理记录
说明
本次训练服务器使用Google Colab T4 GPUBert-VITS2库为:https://github.com/fishaudio/Bert-VITS2,其更新较为频繁,使用其2023.10.12的commit版本:主要参考:B站诸多大佬视频,CSDN:https://blog.csdn.…
首次运行BERT需要的环境配置和准备详细教程,bert运行官方模型,使用MRPC数据集进行测试
第一步 下载所需
下载bert源码和模型 首先我们下载bert的源码和官方的模型,去官网 :
https://github.com/google-research/bert下载官网源码: 下载官方模型: 好好找一下,往下翻翻,肯定有下面这样…
Bert学习笔记(简单入门版)
目 录
一、基础架构
二、输入部分
三、预训练:MLMNSP
3.1 MLM:掩码语言模型
3.1.1 mask模型缺点
3.1.2 mask的概率问题
3.1.3 mask代码实践
3.2 NSP
四、如何微调Bert
五、如何提升BERT下游任务表现
5.1 一般做法
5.2 如何在相同领域数据中进…
pycorrector一键式文本纠错工具,整合了BERT、MacBERT、ELECTRA、ERNIE等多种模型,让您立即享受纠错的便利和效果
pycorrector:一键式文本纠错工具,整合了Kenlm、ConvSeq2Seq、BERT、MacBERT、ELECTRA、ERNIE、Transformer、T5等多种模型,让您立即享受纠错的便利和效果 pycorrector: 中文文本纠错工具。支持中文音似、形似、语法错误纠正,pytho…
大语言模型——BERT和GPT的那些事儿
前言
自然语言处理是人工智能的一个分支。在自然语言处理领域,有两个相当著名的大语言模型——BERT和GPT。两个模型是同一年提出的,那一年BERT以不可抵挡之势,让整个人工智能届为之震动。据说当年BERT的影响力是GPT的十倍以上。而现在&#…
预训练机制(3)~GPT、BERT
目录
1. BERT、GPT 核心思想
1.1 word2vec和ELMo区别 2 GPT编辑
3. Bert
3.1 Bert集大成者
extension:单向编码--双向编码区别
3.2 Bert和GPT、EMLo区别
3.3 Bert Architecture
3.3.1 explanation:是否参数多、数据量大,是否过拟…
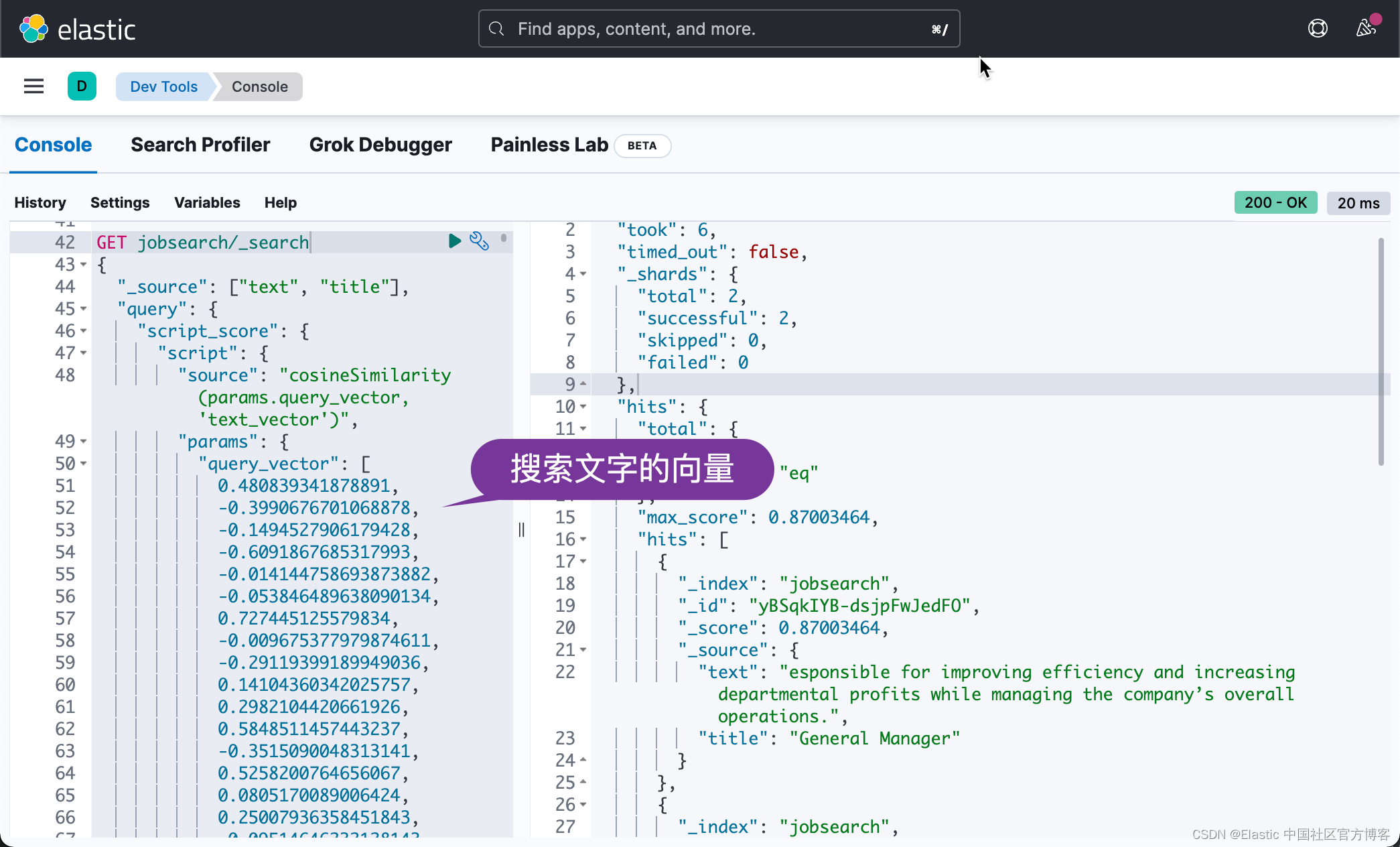
Elasticsearch:使用 Elasticsearch 和 BERT 构建搜索引擎 - TensorFlow
在本文中,我们使用预训练的 BERT 模型和 Elasticsearch 来构建搜索引擎。 Elasticsearch 最近发布了带有向量场的文本相似性(text similarity search with vector field)搜索。 另一方面,您可以使用 BERT 将文本转换为固定长度的向…
Bert基础(十二)--Bert变体之知识蒸馏原理解读
B站视频:https://www.bilibili.com/video/BV1nx4y1v7F5/ 白话知识蒸馏 在前面,我们了解了BERT的工作原理,并探讨了BERT的不同变体。我们学习了如何针对下游任务微调预训练的BERT模型,从而省去从头开始训练BERT的时间。但是&#…
[Attention IS All You Need]Transformer模型有哪些变种
前言及引子 Transformer by google 2017
笔者写下此系列文章是希望在复习人工智能相关知识同时为想学此技术的人提供一定帮助。
本来计划本文接着之前的系列写transformer架构的原理的,但是我觉得transfomer是一个智慧、重要且有些复杂的架构,不先再次…
ALBERT: A LITE BERT FOR SELF-SUPERVISED LEARNING OF LANGUAGE REPRESENTATIONS
原文链接:https://arxiv.org/abs/1909.11942
提出契机
背景:随着BERT模型在多想自然语言处理任务中取得优异表现,很多研究人员开始探索什么样的预训练方法能够帮助模型学习到更好的表示。
该文提出的目的为了降低模型的训练时所占用的内存…
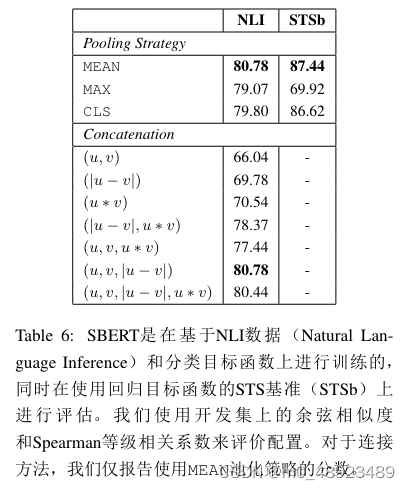
Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks
原文链接:https://arxiv.org/abs/1908.10084
提出契机:
提升相似文本的检索速度
在自然语言处理领域,BERT(Bidirectional Encoder Representations from Transformers)和RoBERTa(A Robustly Optimized B…
使用预训练的bert large model实现问答系统源码(本地实现 question answer system)
pre-trained bert model 预训练好的Bert模型 本地实现问答系统 用这条命令将bert下载到本地: model.save_pretrained("path/to/model")
具体代码 如下链接:
https://download.csdn.net/download/qqqweiweiqq/89092005
BERT入门:理解自然语言处理中的基本概念
1. 自然语言处理简介
自然语言处理(Natural Language Processing,NLP)是人工智能领域的重要分支,涉及计算机与人类自然语言之间的相互作用。NLP 的应用已经深入到我们日常生活中的方方面面,如智能助理、机器翻译、舆情…
BERT论文解读及情感分类实战
文章目录 简介BERT文章主要贡献BERT模型架构技术细节任务1 Masked LM(MLM)任务2 Next Sentence Prediction (NSP)模型输入 下游任务微调GLUE数据集SQuAD v1.1 和 v2.0NER 情感分类实战IMDB影评情感数据集数据集构建模型构建超参数设置训练结果注意事项 简…
预训练的启蒙:浅谈BERT、RoBERTa、ALBERT、T5
文章目录 Transformer揭开预训练序幕为什么RNN/LSTM需要从头训练? BERT核心特点预训练任务架构应用和影响 RoBERTa改进点BERT和RoBERTa的MASK策略对比BERT的静态MASK策略RoBERTa的动态MASK策略效果 总结 ALBERT改进点参数共享因式分解嵌入参数和LoRa对比 总结 T5核心…
BERT常见面试题问题
算法工程师常见面试问题总结之BERT面试常见问题总结 1.简单描述下BERT的结构 答:BERT是Google在2018年提出的一种基于Transformers的预训练语言模型。BERT的设计理念是通过大规模无标注语料库的预训练,使得模型能够学习到丰富的语言知识,并将…

基于 Bert 论文构建 Question-Answering 模型
访问【WRITE-BUG数字空间】_[内附完整源码和文档]
摘要 本文拜读了提出 Bert 模型的论文,考虑了在 Bert 中算法模型的实现.比较了 Bert 与其他如 Transformer、GPT 等热门 NLP 模型.BERT 在概念上很简单,在经验上也很强大。它推动了 11 项自然语言处理任…

初探BERTPre-trainSelf-supervise
初探Bert
因为一次偶然的原因,自己有再次对Bert有了一个更深层地了解,特别是对预训练这个概念,首先说明,自己是看了李宏毅老师的讲解,这里只是尝试进行简单的总结复述并加一些自己的看法。
说Bert之前不得不说现在的…
深入理解深度学习——BERT派生模型:BART(Bidirectional and Auto-Regressive Transformers)
分类目录:《深入理解深度学习》总目录 UniLM和XLNet都尝试在一定程度上融合BERT的双向编码思想,以及GPT的单向编码思想,同时兼具自编码的语义理解能力和自回归的文本生成能力。由脸书公司提出的BART(Bidirectional and Auto-Regre…
BERT数据处理,模型,预训练
代码来自李沐老师《动手学pytorch》
在数据处理时,首先执行以下代码
def load_data_wiki(batch_size, max_len):"""加载WikiText-2数据集"""num_workers d2l.get_dataloader_workers()data_dir d2l.download_extract(wikitext-2, w…
使用bert进行文本二分类
构建BERT(Bidirectional Encoder Representations from Transformers)的训练网络可以使用PyTorch来实现。下面是一个简单的示例代码:
import torch
import torch.nn as nn
from transformers import BertModel, BertTokenizer# Load BERT to…
ChatGLM 实现一个BERT
前言 本文包含大量源码和讲解,通过段落和横线分割了各个模块,同时网站配备了侧边栏,帮助大家在各个小节中快速跳转,希望大家阅读完能对BERT有深刻的了解。同时建议通过pycharm、vscode等工具对bert源码进行单步调试,调试到对应的模块再对比看本章节的讲解。 涉及到的jupyt…
Bert文本聚类实践
问题来源:先做的huggingface-bert文本分类(参考text-classification,情感分类,数据集可以考虑SST2),但是数据量太大了,无法穷举所有的类别,故而先用分类来做,但这样也有一…
bert新闻标题分类
使用 bert 完成文本分类任务,数据有 20w,来自https://github.com/649453932/Bert-Chinese-Text-Classification-Pytorch/tree/master/THUCNews 下载即可: 模型使用 bert-base-chinese 下载参考:bert预训练模型下载-CSDN博客 实现了…
BERT网络的原理与实战
BERT网络的原理与实战 一、简介二、原理1. Transformer2. BERT2.1 MLM2.2 NSP 3. Fine-tuning 三、实战1. 数据集2. 预处理3. 模型训练 一、简介
BERT(Bidirectional Encoder Representations from Transformers)是一种基于Transformer架构的预训练语言…

大数据知识图谱之深度学习——基于BERT+LSTM+CRF深度学习识别模型医疗知识图谱问答可视化系统
文章目录 大数据知识图谱之深度学习——基于BERTLSTMCRF深度学习识别模型医疗知识图谱问答可视化系统一、项目概述二、系统实现基本流程三、项目工具所用的版本号四、所需要软件的安装和使用五、开发技术简介Django技术介绍Neo4j数据库Bootstrap4框架Echarts简介Navicat Premiu…
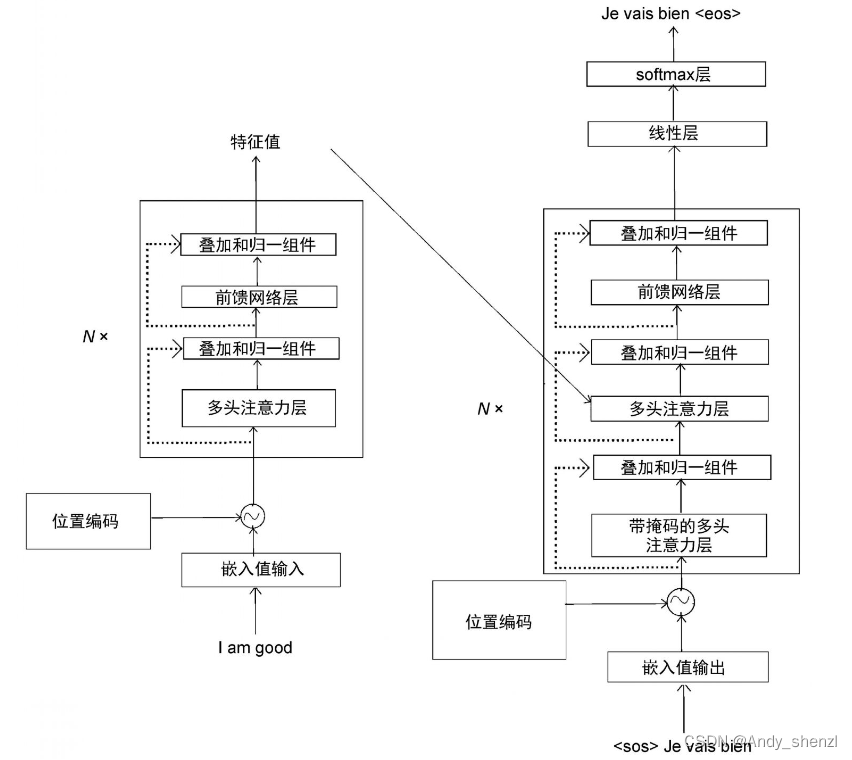
Bert基础(五)--解码器(下)
1、 多头注意力层
下图展示了Transformer模型中的编码器和解码器。我们可以看到,每个解码器中的多头注意力层都有两个输入:一个来自带掩码的多头注意力层,另一个是编码器输出的特征值。 让我们用R来表示编码器输出的特征值,用M来…

Bert-as-service 实战
参考:bert-as-service 详细使用指南写给初学者-CSDN博客
GitHub - ymcui/Chinese-BERT-wwm: Pre-Training with Whole Word Masking for Chinese BERT(中文BERT-wwm系列模型)
下载:https://storage.googleapis.com/bert_models/…
Transformer、BERT和GPT 自然语言处理领域的重要模型
Transformer、BERT和GPT都是自然语言处理领域的重要模型,它们之间有一些区别和联系。
区别:
架构:Transformer是一种基于自注意力机制的神经网络架构,用于编码输入序列和解码输出序列。BERT(Bidirectional Encoder R…
使用 BERT 进行文本分类 (03/3)
一、说明 在使用BERT(2)进行文本分类时,我们讨论了什么是PyTorch以及如何预处理我们的数据,以便可以使用BERT模型对其进行分析。在这篇文章中,我将向您展示如何训练分类器并对其进行评估。
二、准备数据的又一个步骤 …

NLP 算法实战项目:使用 BERT 进行模型微调,进行文本情感分析
本篇我们使用公开的微博数据集(weibo_senti_100k)进行训练,此数据集已经进行标注,0: 负面情绪,1:正面情绪。数据集共计82718条(包含标题)。如下图: 下面我们使用bert-base-chinese预训练模型进行微调并进行测试。 技术交流&#x…
gunicorn+flask使用问题修复方案
来源:torch模型在线推理采用gunicornflask部署API服务问题简述:torch模型——huggingface bert模型,CPU核数964个GPU同时使用,启动worker80左右(80个并发请求),前期能够调用GPU,后期发现有些进程重启后就不…
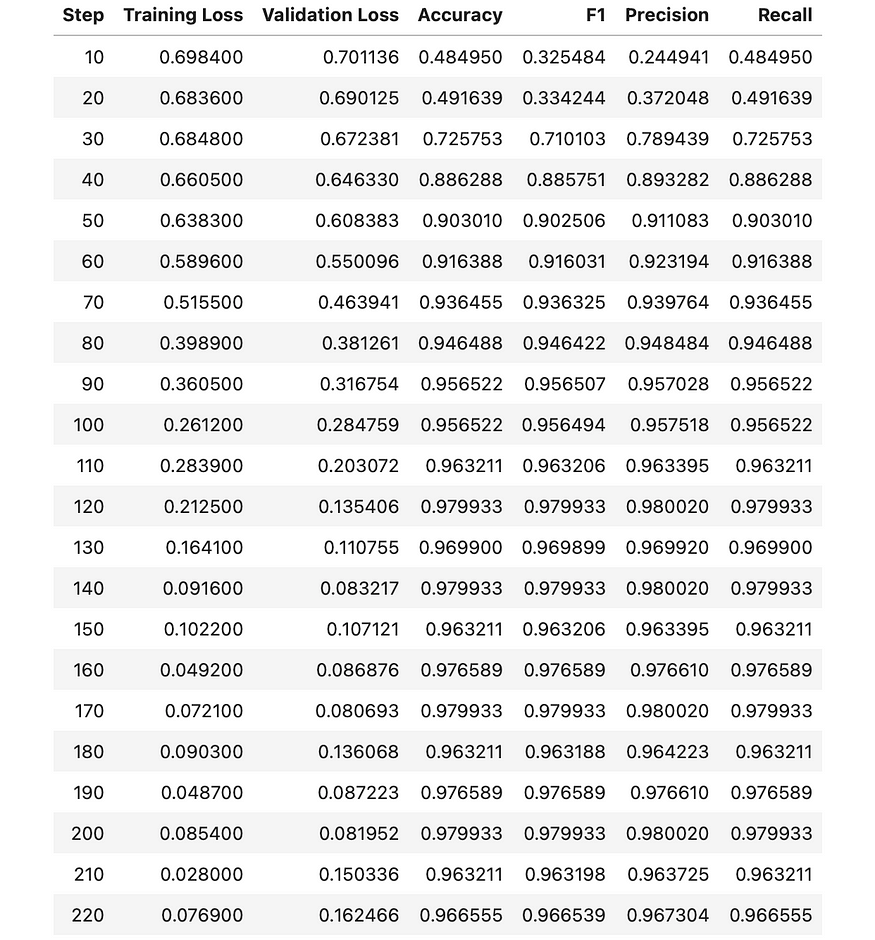
精读 Generating Mammography Reports from Multi-view Mammograms with BERT
精读(非常推荐) Generating Mammography Reports from Multi-view Mammograms with BERT(上)
这里的作者有个叫 Ilya 的吓坏我了
1. Abstract
Writing mammography reports can be errorprone and time-consuming for radiolog…
大语言模型LLM知多少?
你知道哪些流行的大语言模型?你都体验过哪写? GPT-4,Llamma2, T5, BERT 还是 BART?
1.GPT-4
1.1.GPT-4 模型介绍
GPT-4(Generative Pre-trained Transformer 4)是由OpenAI开发的一种大型语言模型。GPT-4是前作GPT系列模型的进一步改进,旨在提高语言理解和生成的能力,…
基于BERTopic模型的英文20新闻数据集主题聚类及可视化
文章目录 bertopic介绍20 newsgroups dataset20 newsgroups数据集下载数据导入nltk数据处理bertopic模型构建模型训练运行模型可视化目前主题的一致性得分语料库建模bertopic介绍
BERTopic 是基于深度学习的一种主题建模方法。BERT 是一种用于 NLP 的预训练策略,它成功地利用…
NLP之Bert实现文本多分类
文章目录 代码代码整体流程解读debug上面的代码 代码
from pypro.chapters03.demo03_数据获取与处理 import train_list, label_list, val_train_list, val_label_list
import tensorflow as tf
from transformers import TFBertForSequenceClassificationbert_model "b…
Bert基础(八)--Bert实战之理解Bert微调
到目前为止,我们已经介绍了如何使用预训练的BERT模型。现在,我们将学习如何针对下游任务微调预训练的BERT模型。需要注意的是,微调并非需要我们从头开始训练BERT模型,而是使用预训练的BERT模型,并根据任务需要更新模型…
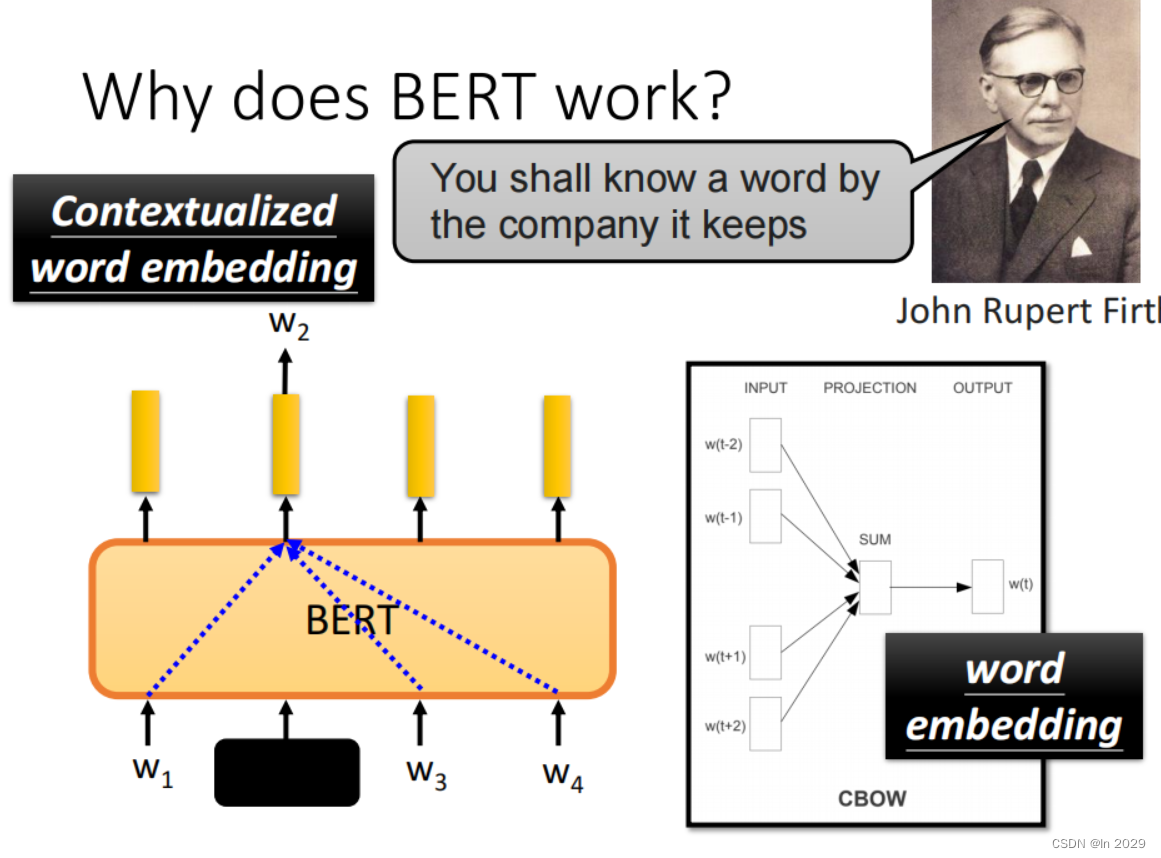
BERT学习【BERT的例子以及作用】
一、case
1.case1
多输入单输出。通过输入一个句子(sequence),然后输出一个句子的分类(这个句子是正向还是负向)。将句子输入BERT,然后通过softmax输出分类。
2.case2
多输入多输出。输入一个句子&…
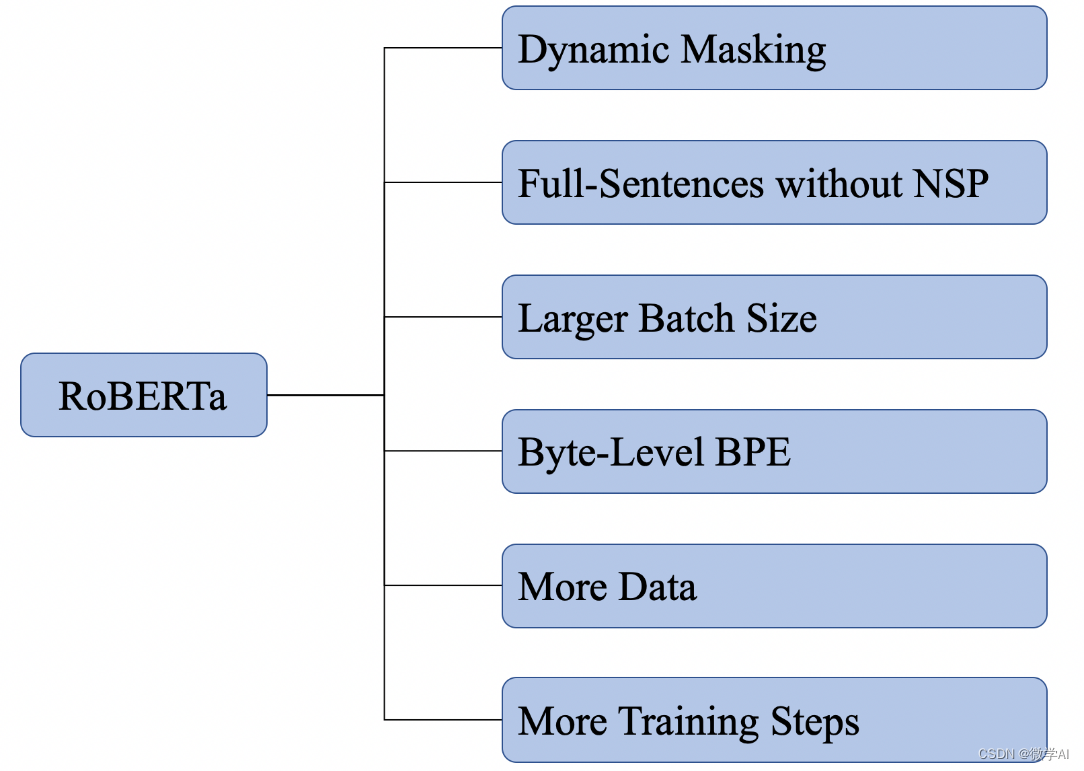
自然语言处理实战项目28-RoBERTa模型在BERT的基础上的改进与架构说明,RoBERTa模型的搭建
大家好,我是微学AI,今天给大家介绍下自然语言处理实战项目28-RoBERTa模型在BERT的基础上的改进与架构说明,RoBERTa模型的搭建。在BERT的基础上,RoBERTa进行了深度优化和改进,使其在多项NLP任务中取得了卓越的成绩。接下来,我们将详细了解RoBERTa的原理、架构以及它在BERT…
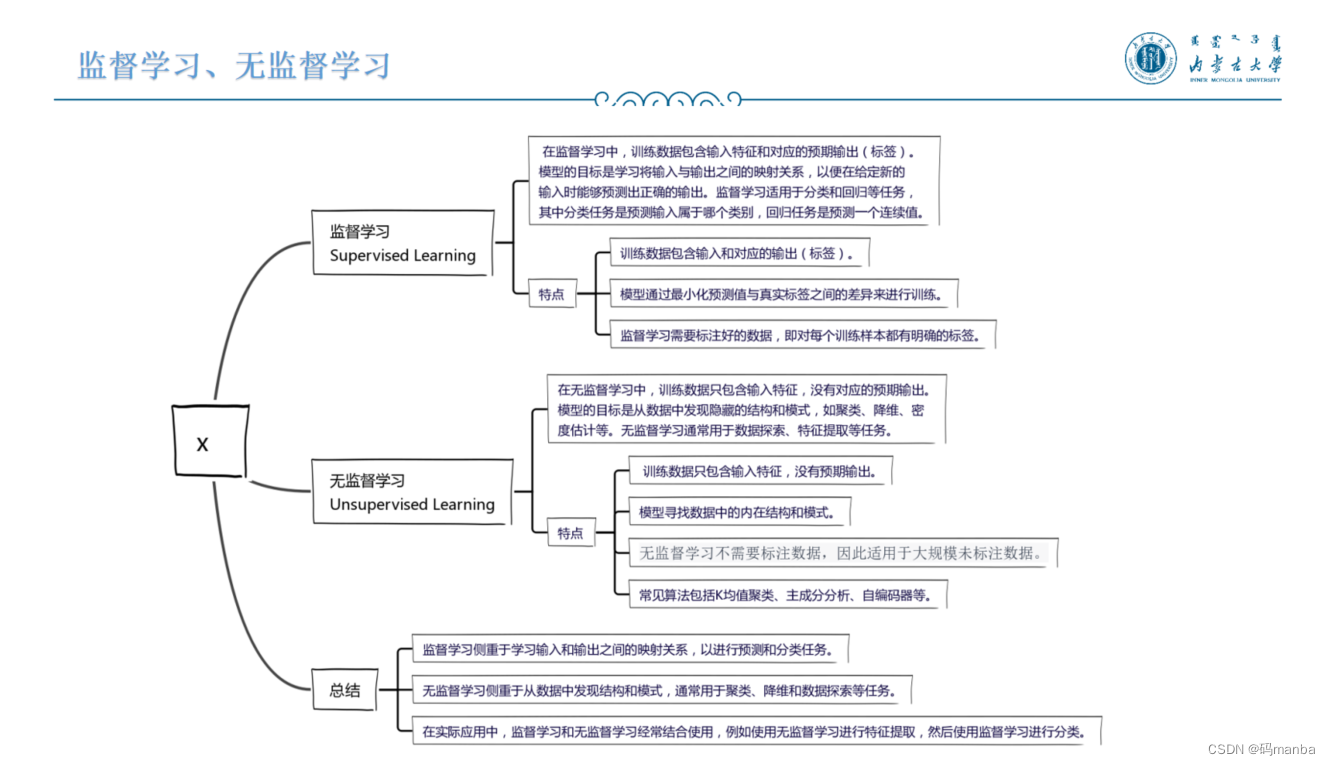
GloVe、子词嵌入、BPE字节对编码、BERT相关知识(第十四次组会)
GloVe、子词嵌入、BPE字节对编码、BERT相关知识(第十四次组会) Glove子词嵌入上游、下游任务监督学习、无监督学习BERTGlove 子词嵌入 上游、下游任务 监督学习、无监督学习 BERT
【ACL 2023获奖论文】再现奖:Do CoNLL-2003 Named Entity Taggers Still Work Well in 2023?
【ACL 2023获奖论文】再现奖:Do CoNLL-2003 Named Entity Taggers Still Work Well in 2023? 写在最前面动机主要发现和观点总结 正文1引言6 相关工作解读 2 注释一个新的测试集以度量泛化CoNLL数据集的创建数据集统计注释质量与评估者间协议目标与意义 3 实验装置…

第六十三回 呼延灼月夜赚关胜 宋公明雪天擒索超-大模型BERT、ERNIE、GPT和GLM的前世今生
神行太保戴宗报信,关胜人马直奔梁上泊,请宋江早早收兵,解梁山之难。宋江派了花荣到飞虎峪左边埋伏,林冲到右边埋伏,再叫呼延灼带着凌振,在离城十里附近布置了火炮,然后才令大军撤退。
李成闻达…

HuggingFace-利用BERT预训练模型实现中文情感分类(下游任务)
准备数据集
使用编码工具
首先需要加载编码工具,编码工具可以将抽象的文字转成数字,便于神经网络后续的处理,其代码如下:
# 定义数据集
from transformers import BertTokenizer, BertModel, AdamW
# 加载tokenizer
token Ber…
机器学习深度学习——针对序列级和词元级应用微调BERT
👨🎓作者简介:一位即将上大四,正专攻机器学习的保研er 🌌上期文章:机器学习&&深度学习——NLP实战(自然语言推断——注意力机制实现) 📚订阅专栏:机…
BERT 上的动态量化
(实验)BERT 上的动态量化
介绍
在本教程中,我们将动态量化应用在 BERT 模型上,紧跟 HuggingFace Transformers 示例中的 BERT 模型。 通过这一循序渐进的过程,我们将演示如何将 BERT 等众所周知的最新模型转换为动态量化模型。 …
HuggingFace-利用BERT预训练模型实现中文情感分类(下游任务)
准备数据集
使用编码工具
首先需要加载编码工具,编码工具可以将抽象的文字转成数字,便于神经网络后续的处理,其代码如下:
# 定义数据集
from transformers import BertTokenizer, BertModel, AdamW
# 加载tokenizer
token Ber…
NLP---Bert分词
目录: Q:bert分词步骤1:构建N * N 的相关性矩阵,计算相邻两个字的相关性,低的话(<阈值)就切割。2:将A词进行mask计算出A的embedding,然后将AB两个词一起maskÿ…

Bert-vits2新版本V2.1英文模型本地训练以及中英文混合推理(mix)
中英文混合输出是文本转语音(TTS)项目中很常见的需求场景,尤其在技术文章或者技术视频领域里,其中文文本中一定会夹杂着海量的英文单词,我们当然不希望AI口播只会念中文,Bert-vits2老版本(2.0以下版本)并不支持英文训练和推理&…
BERT 论文阅读笔记
文章目录 前言论文阅读同类工作比较模型架构训练方式使用步骤实验结果 其他 前言
BERT是在NLP领域中第一个预训练好的大型神经网络,可以通过模型微调的方式应用于后续很多下游任务中,从而避免了下游NLP应用需要单独构建一个新的神经网络进行复杂的预训练…
[Python人工智能] 四十四.命名实体识别 (5)利用bert4keras构建Bert-CRF实体识别模型(实体位置)
从本专栏开始,作者正式研究Python深度学习、神经网络及人工智能相关知识。前文讲解如何实现中文命名实体识别研究,构建BiGRU-CRF模型实现。这篇文章将继续以中文语料为主,介绍融合Bert的实体识别研究,使用bert4keras和kears包来构建Bert+BiLSTM-CRF模型。然而,该代码最终结…

Transformers-Bert家族系列算法汇总
🤗 Transformers 提供 API 和工具,可轻松下载和训练最先进的预训练模型。使用预训练模型可以降低计算成本、碳足迹,并节省从头开始训练模型所需的时间和资源。这些模型支持不同形式的常见任务,例如:
📝 自…
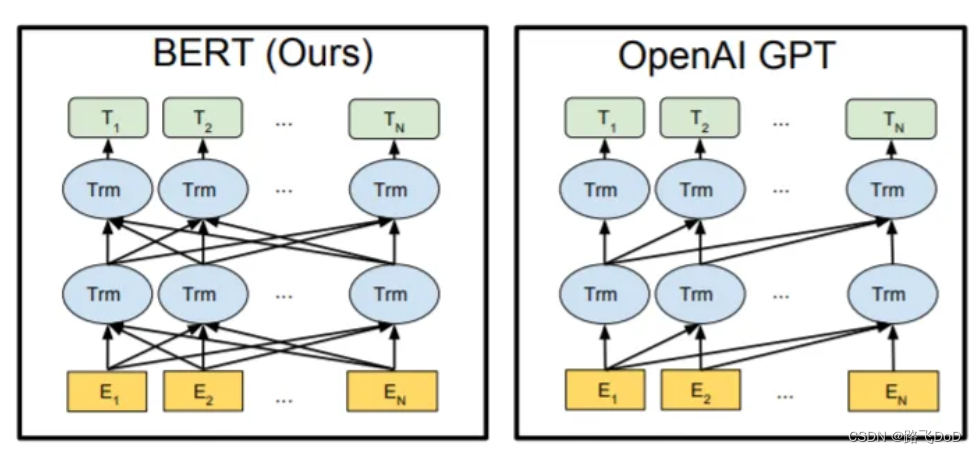
what is BERT?
BERT
Introduction
Paper
参考博客
9781838821593_ColorImages.pdf (packt-cdn.com) Bidirectional Encoder Representation from Transformer 来自Transformer的双向编码器表征 基于上下文(context-based)的嵌入模型。
那么基于上下文(…
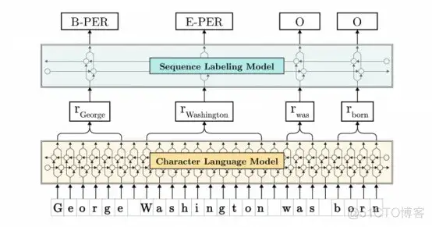
性能优于BERT的FLAIR:一篇文章入门Flair模型
文章目录 What is FLAIR?FLAIR ModelContextual String Embedding for Sequence Labelingexample FLAIR Application AreaSentiment AnalysisNamed Entity RecognitionText Classification FLAIR一、什么是FLAIR?二、FLAIR Library的优势是什么ÿ…
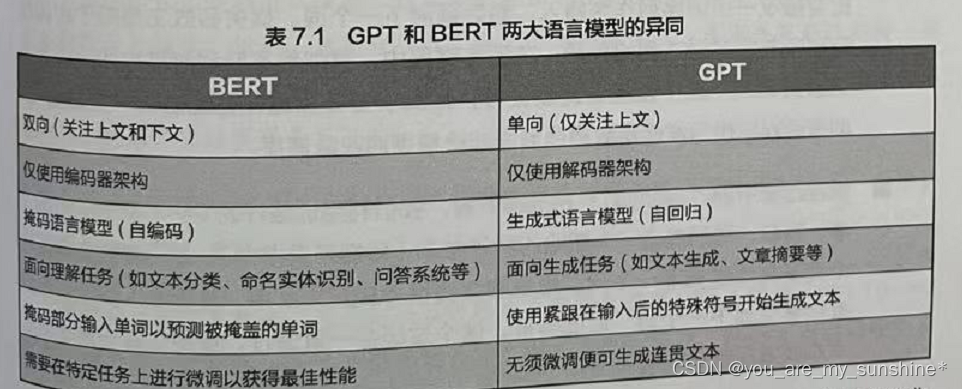
NLP_BERT与GPT争锋
文章目录 介绍小结 介绍
在开始训练GPT之前,我们先比较一下BERT和 GPT 这两种基于 Transformer 的预训练模型结构,找出它们的异同。
Transformer架构被提出后不久,一大批基于这个架构的预训练模型就如雨后春笋般地出现了。其中最重要、影响…
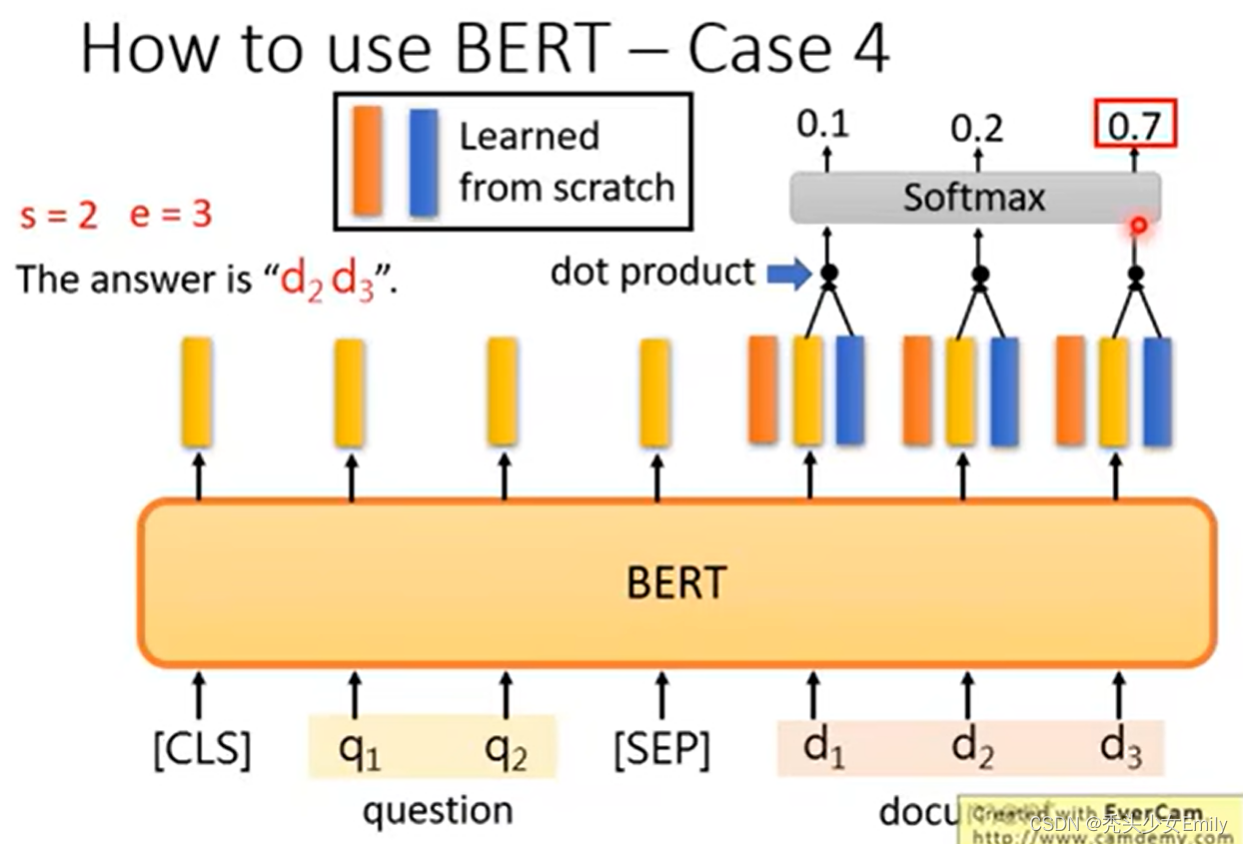
【李沐精读系列】BERT精读
论文:BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding 参考:BERT论文逐段精读、李沐精读系列、李宏毅版BERT讲解 一、介绍 BERT(Bidirectional EncoderRepresentation Transformer,双向Transformer编码器…
bert 适合 embedding 的模型
目录
背景
embedding
求最相似的 topk
结果查看 背景
想要求两个文本的相似度,就单纯相似度,不要语义相似度,直接使用 bert 先 embedding 然后找出相似的文本,效果都不太好,试过 bert-base-chinese,be…

BERT模型中句子Tokenize和ID转换的过程
当我们使用BERT或其他类似的预训练语言模型时,将句子转换为token的过程通常涉及以下几个步骤: 初始化Tokenizer:首先,我们需要导入相应的Tokenizer类,并根据需求选择合适的预训练模型进行初始化。 分词(To…

【Transformer】Transformer and BERT(1)
文章目录 TransformerBERT 太…完整了!同济大佬唐宇迪博士终于把【Transformer】入门到精通全套课程分享出来了,最新前沿方向
学习笔记
Transformer 无法并行,层数比较少 词向量生成之后,不会变,没有结合语境信息的情…